În urma sesizării unui profesionist în Excel am identificat că articolul acesta și metoda propusă sunt eronate pentru că nu generează toate combinațiile posibile.
Ca să respectăm matematica numărul de combinații maxime rămâne limitat la 189 (momentan) având în vedere că valoarea lui COMPIN(190;3) este mai mare decât 2^20.
[/UPDATE]
Astăzi nu am mai reușit să programez o sesiune O oră de Excel. Program foarte încărcat, între care o întâlnire cu boardul RCW (Romanian Creative Week) pentru organizarea în facultatea noastră a celei de a doua ediții a evenimentului: UniCredit Fintech Hackathon
Dar am reușit în timp ce rezolvam alte probleme să găsesc o formă optimizată a matricei de triplete în Excel.
La ce este bună această matrice?
Explicam în articolul din PIN Magazine – Programarea funcțională în Excel Modern că în Excel nu avem o funcție FOR() baza iterațiilor în, cred, toate limbajele de programare actuale. Dar avem soluții detaliate în acel articol. Marea problemă a versiunii prezentate acolo dar și în articolele despre algoritmi din acest blog, este limitarea numărului de elemente dintr-un vector pe care le poți prelucra. În acea primă versiune funcția putea genera matrice de triplete pentru maximum 101 elemente ale unui vector.
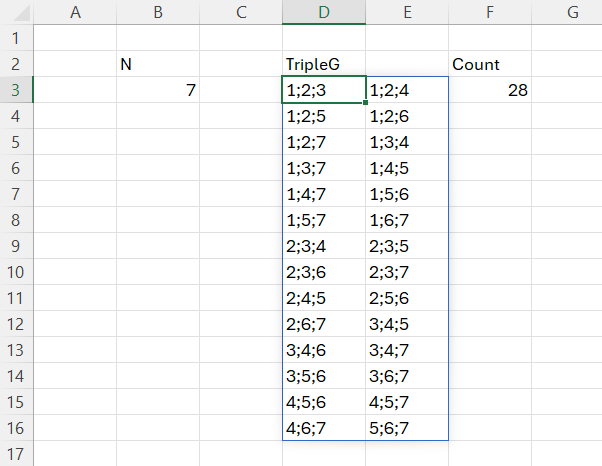
Scopul acestor matrici este intermediar pentru prelucrarea unor seturi de numere luate câtre 3, fără repetiții. Ai un șir de numere și vrei să le adune pe toate cu alte câte două fără să repeți secvența. Cum faci? Ca să iei toate combinațiile unice de câte 3 trebuie să indexezi vectorul, iar pentru asta trebuie să știi ce poziții să apelezi. Acesta este scopul acestui algoritm: determinarea tuturor combinațiilor de poziții ale unui vector, luate câte 3.
Noua variantă elimină funcția SCAN() și introduce o matrice generată. Matricea este foarte mare consumatoare de resuse dar depășește limitele impuse până la versiunile curente.
Exemplificare în Excel
În acestă imagine am prezentat rezultatul pe două coloane ca să ocupe mai puțin spațiu.
în care cheia este variabila matrix care conține funcția MAKEARRAY() care generează dinamic toate combinațiile de numere și asta având doar 2 variabile r și c din care generez cele 3 numere _n1, _n2, _n3. Este o aplatizarea de fapt a unei dimensiuni 3D într-un plan RxC.
Ca să pot sorta elementele am utilizat funcția recursivă freq în care splitez orice valoare rezultată în matrice ca să o pot sorta, după care în variabila finală TripleG păstrez doar valorile unice.
Vizual codul dacă nu apare corect în scriptul de mai sus:
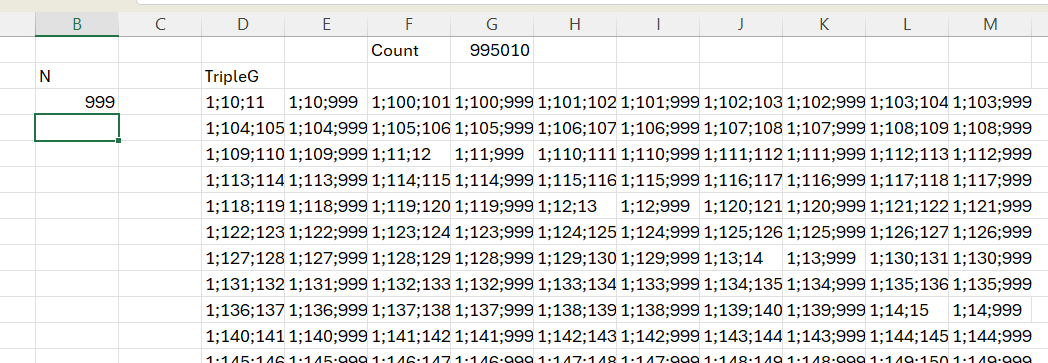
Exemplificare rulare la 999 elemente. Aici se observă că există o mică problemă de sortare a numerelor pentru că ele sunt tratate ca valori text în urma concatenărilor.
Cam asta ar fi. Makearray() rămâne una din funcțiile cele mai surprinzătoare până acum din ceea ce am descoperit recent.
În urmă cu ceva ani, unul din profesorii mei preferați (am mai mulți) ne povestea despre chinurile proiectării și implementării unui „motoraș” de repartizare a opțiunilor studenților sau candidaților pe anumite locuri în ordinea mediilor și preferințelor. Prima dată l-a făcut în SQL pentru admiterea la facultate. Ulterior l-a făcut în R. Recunosc că am privit oarecum cu invidie, pentru că în SQL chiar dacă am învățat destul de bine la master, nu am reușit să îl implementez, iar partea de R nu am înțeles-o prea bine, chiar dacă am mai cochetat din când în când.
Însă din momentul în care am început cercetarea profundă a programării funcționale în Excel, am reușit să fac lucruri pe care altă dată doar le visam și asta fără ajutorul generatoarelor de text, care sunt depășite de aceste metode. I-am mai spus lui ChatGPT că în Excel NU există FOR. El o ține pe a lui. Nu recomand! :)
Acest articol este un tribut pentru toți profesorii (unii actuali colegi ai mei) care m-au îndrumat și încurajat de-a lungul timpului să performez.
Fișierul de lucru poate fi accesat și descărcat de la adresa: AlocareOptiuni v1.xlsx. Acest fișier funcționează doar în versiunile Office 365 sau versiunile mai noi care suport funcții dinamice.
Proiecția problemei în Excel
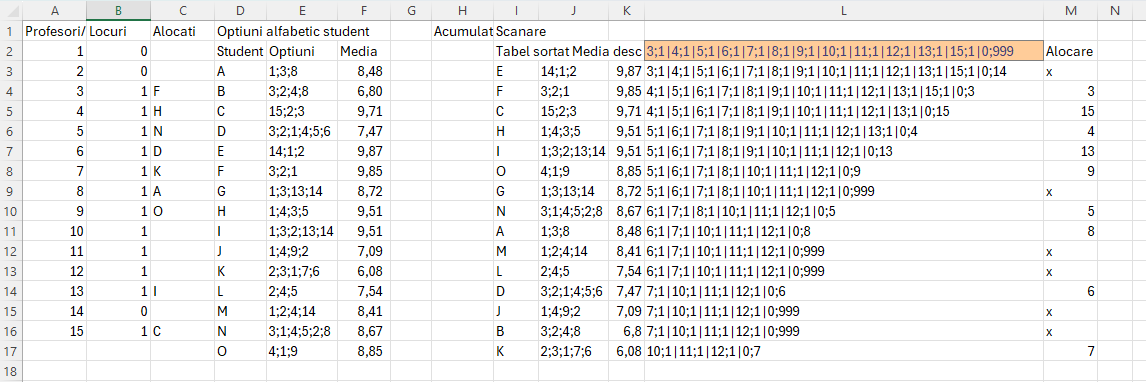
În exemplul prezentat în fișier, se presupune că avem o listă de profesori care au disponibile teme pentru lucrările de licență și un anumit număr de locuri pe fiecare temă. Ca să poată funcționa algoritmul propus, este esențial să codificăm fiecare temă în mod numeric. Numărul de locuri le specificăm tot numeric în dreptul codului fiecărei teme. Temele cu 0 locuri vor fi excluse automat din motorașul de repartizare.
Opțiunile studenților sunt prezentate ca un șir de opțiuni delimitate prin ; (punct și virgulă) în care fiecare număr este codul unei teme. Algoritmul aranjează sursa de date în ordine descrescătoare a mediilor după care face repartizarea după prima opțiune, apoi a doua dacă la prima opțiune nu mai sunt locuri și așa mai departe.
Funcția pe care o puteți întâlni și în fișierul Excel în celula K2 este:
în care:
locs este blocul de teme de la A2:B21 și care trebuie înlocuit în funcție cu propriile coduri
optiuni sunt numele studenților cu opțiunile lor și media. Există și posibilitatea de a aborda alocarea și în funcție de principiul primul venit primul servit. În acest caz, dacă ordinea este cea prezentată în foaia de calcul, trebuie să modificăm valorile de pe coloana G cu numere descrescătoare.
Pentru a reduce complexitatea și numărul de caractere, am definit la începutul formulei, 4 funcții recursive: _fCumulare(tab), _fDecumulare(acumulate), _fLast(x) și _fLastN(x) pe care le utilizez în _scan cu precădere și în result.
Explicam în articolele trecute că un SCAN() nu poate lucra cu tabele ci doar cu o singură valoare. Ca să pot scana totuși tabele întregi, am nevoie de a unifica aceste tabele în valori parsabile.
Prin cod se observă un 999 la linia 8, în _scan și apoi în result. Acest 999 mă ajută să determin dacă o opțiune este în afara numărului de locuri disponibile.
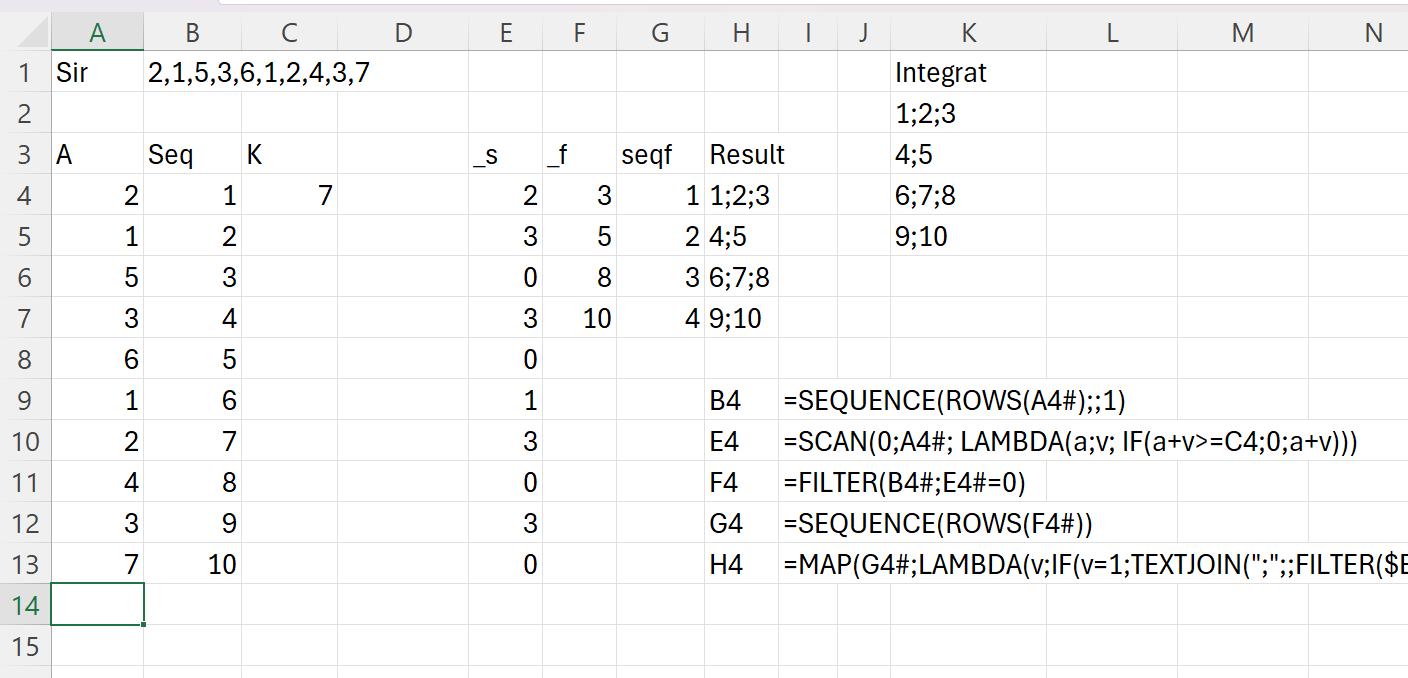
Complexitatea acelui SCAN() poate fi văzută într-o proiecție intermediară aici:
Valoarea de final a fiecărui șir intermediar (acumulatorul din SCAN) este o combinație de 0 și rezultatul prelucrării: 999 sau valoarea opțiunii care îndeplinește criteriile alocării pentru acel student.
În momentul în care am alocat un loc, ca să pot face scăderea lui din locurile rămase am apelat la scăderea a două matrici în variabila ramase (linia 19) care adună rezultatul decumulării acumulatorului curent din intro (linia 12) cu o matrice cu două coloane generată dinamic în funcție de numărul de linii rămase din intro.
Vizual această oprațiune de scădere a matricilor ar fi:
Această tehnică mi-a permis să am oricâte opțiuni din partea unui student și să le tratez pe toate în funcție de ce a mai rămas în acumulator.
Chinul cel mare nu a fost la SCAN ci la integrarea rezultatelor în aceeași formulă. În versiunile intermediare MAP() era soluția logică la calculul variabilei resut. Până la urmă l-am folosit, dar am lucrat doar cu șiruri fără reutilizare funcțiilor de Cumulare și Decumulare. Efectiv nu poți într-un MAP dintr-un LET să folosești rezultatul intermediar al lui SCAN pe care sa-l transformi din nou în tabelar, chiar dacă rezultatul în proiectezi ca valoare atomică cumulată.
În celula C2 pentru a calcula pentru fiecare temă studenții alocați am implementat un simplu TEXTJOIN() de filtrare. Formula din C2: =TEXTJOIN(„;”;;FILTER($K$2:$K$18;$L$2:$L$18=A2;””)). Trebuie să modificați adresele dacă aveți mai multe sau mai puține opțiuni.
Cam asta ar fi.. cazurile de aplicare pot fi diverse, important este să aranjam datele de intrare corect dacă dorim să utilizăm acest „motoraș” de repartizare.
Un algoritm greedy este o strategie de rezolvare a problemelor care face alegeri pas cu pas, selectând în fiecare moment opțiunea cea mai bună disponibilă, fără a lua în considerare deciziile viitoare.
Principiul de bază este: „Alege ceea ce pare a fi cea mai bună opțiune la fiecare pas, sperând că această strategie va duce la soluția optimă.”
Acești algoritmi sunt simpli și eficienți, dar nu garantează întotdeauna cea mai bună soluție globală.
În Excel nu avem posibilitatea de a face alegeri numaidecât locale, ci problemele trebuie trate la nivel global. Da o strrategie eficientă este să rezolvi pas cu pas problema, din aproape în aproape pentru a putea ajunge la o soluție integrată. Chiar și în rezolvările individuale trebuie să avem în vedere funcții reutilizabile și tratarea globală a vectorilor de input. De aceea în toată această tehnică este esențială funcția MAP() pentru parcurgerea element cu element a unui vector sau SCAN() tot pentru parcurgere globală, dar cu avantajul acumulării.
Un pic de teorie aplicată
În această secțiune doar voi reaminti cum funcționează o funcție MAP(), SCAN() și BYROW().
Foarte important: Nici una din funcții NU generează tabele. De aceea, în exemplele mele vedeți foarte mult TEXTJOIN() și TEXTSPLIT() ca să pot acumula rezultatele intermediare într-o singură valoare. Dar ca să le pot prelucra trebuie să le splitez ca numere.
MAP() este o funcție care parcurge un vector valoare cu valoare de sus în jos. În multe cazuri putem folosi MAP() pentru a scana un fake vector, generat de exemplu de o funcție SEQUENCE pentru a putea face căutare și înainte pe un vector de valori. De cele mai multe ori dacă dorim să obținem printr-o singură formulă un tabel trebuie să le încapsulăm într-un LET(). Nu am exemple în acest moment despre combinații între MAP() și SCAN(). De obicei eu personal aleg să le tratez separat sau să se separ în funcții recursive distincte.
REPT() este o funcție de replicare a unui șir de un număr specificat de ori.
BYROW() este o funcție care tratează un tabel de date linie cu linie. Similar cu BYROW este BYCOL(). Când dorim să facem calcule simple, atunci putem specifica direct funcția după specificarea tabelului. Dacă avem veva mai mult de calcul, sintaxa generală este: =BYROW(tabel; LAMBDA(linie; calcule))
Funcția TAKE(), CHOOSECOL() sau INDEX() au un rol important în tratarea element cu element a unei linii.
Acestea fiind spuse o să încep atipic această rezolvare cu a doua problemă… pentru că este mai simplă.
Problema TieRopes
Presupune să se determine numărul de funii de o anumită lungime K specificată care pot fi create prin însumarea (înodarea) capetelor dintr-un șir de valori date (A). Valoarea capetelor nu poate depăși K dar funiile pot avea dimensiuni mai mari sau egale cu K. Ordinea de însumare este consecutivă nu se acceptă ca un segment A[0] să fie legat de un alt segment A[n].
Rezolvarea problemei în Excel este foarte simplă, dar rezultatele obținute prin rezolvare locală (subșiruri continue fără verificare globală înainte și înapoi) pot fi oarecum discutabile.
Pornind de la șirul din B2, l-am descompus în A4 apoi am calculat secvența cu start de la 1 în B4. Cheia problemei este în E4 unde prin SCAN am comparat sumele acumulate până în prezent din vectorul A cu valoarea lui K (dimensiunea minimă a unei funii). Ca să pot oferi rezultatele în format de segmente, în H4 am utilizat următoarea formulă:
În care scanez vectorul din G3 rezultat în urma prelucrărilor și pe baza valorii acestui vector concatenez cu TEXTJOIN() valorile de până în acel moment.
Formula integrată pornind de la șirul din B2 și valoarea lui K din C4 este:
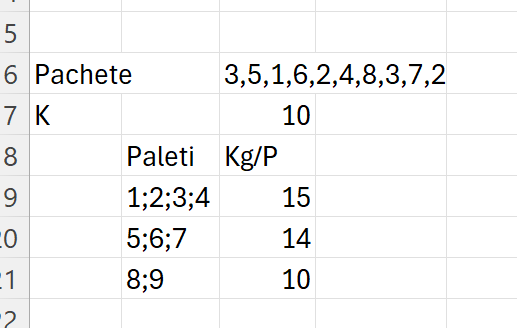
Presupunem că avem un lanț de aprovizionare logistic pentru un retailer care trebuie să transporte pachete mici de produse între depozite și punctele de vânzare. Aceste pachete au greutăți variabile, iar pentru a reduce costurile de transport, ele trebuie grupate în unități mai mari, dar respectând anumite restricții minime de greutate pentru eficiență.
Sintetizând descrierea trebuie să respectăm condițiile:
Fiecare palet să aibă o greutate minimă K pentru ca transportul să fie eficient (sub această valoare, paletul nu este rentabil).
Trebuie să formăm cât mai mulți paleți, pentru a maximiza utilizarea spațiului din camion și a reduce numărul de transporturi.
Exemplu concret de date: Să presupunem că avem un set de 10 pachete cu următoarele greutăți (în kg): A=[3,5,1,6,2,4,8,3,7,2] și greutatea minimă necesară pentru transport eficient este K=10 kg.
Rezolvarea este foarte simplă:
în care pentru a calcula numărul de kg pe fiecare palet am introdus o nouă variabilă în funcția prezentată anterior:
care presupune însumarea valorilor coletelor din șirul dat.
Problema MaxNonoverlappingSegments
Problema aceasta a fost un coșmar din punct de vedere al prelucrărilor. 100% rezolvarea ei în Excel este doar un exercițiu de manipulare de date și rezultate, fără a avea pretenții de optimizare.
Problema MaxNonoverlappingSegments este o problemă clasică de optimizare care face parte din categoria Greedy algorithms (algoritmi lacomi). Aceasta constă în selectarea unui număr maxim de segmente (intervale) care nu se suprapun, dintr-un set de segmente date.
Avem o serie de segmente definite prin capete (start și end points), fiecare segment fiind reprezentat printr-o pereche de numere: (A[i],B[i]) unde:
A[i] este punctul de început al segmentului.
B[i] este punctul de sfârșit al segmentului.
Obiectivul este să alegem cât mai multe segmente care nu se suprapun, adică nu au puncte comune, astfel încât să maximizăm numărul total de segmente selectate.
O chichiță a problemei este dată de faptul că rezultatul final trebuie să fie prezentat în segmente de câte 3 și în combinații de câte 3 trebuie să prezentăm output-ul.
În imagine este prezentată rezolvarea graduală a problemei, proiecții intermediare pas cu pas, până a ajunge la forma finală din aproape în aproape.
Așa cum explicam în partea de teorie a acestui articol, cheia rezolvării constă în utilizarea funcției MAP și consțientizarea faptului că rezultatul trebuie să fie permanent o singură valoare.
Având în vedere că trebuie să returnăm valorile în seturi de câte 3 a trebuit să introduc și să salvez funcția _fTripleMatrix(elem) prezentată în aceste articole, care are următorul cod:
în care elem este o valoare mai mare decât 3 și, așa cum explicam cu alte ocazii, poate avea un maxim de 189 pentru că numărul de combinații de 190 luate câte 3 depășește valoarea 2^20 care este numărul de linii dintr-o foaie de calcul Excel. Ca o curiozitate, în Google Spreadheet nu am reușit să generez o secvență de numere mai mare de 2^15.
Cheia rezolvării problemei este identificarea capetelor și intersecția lor cu alte segmente. Această secțiune este rezolvată în F5 și G5 printr-o funcție de mapare în care valoare 1 presupune intsecție cu alt interval, iar 0 lipsa intersecției. Dacă suma ambelor segmente se regăsește pe celălalt segment, atunci valoarea 2 ne spune că avem o intersecție. Valoarea 1 ne spune că acel segment nu se intersectează cu altul. Și de aici încep tot felul de calcule și filtre, mapări pe matricea de triplete dinamică și așa mai departe.
O parte complexă din formulă este definirea funcției recursive _freqBR care înglobează funcția _fTripleMatrix() definită anterior. Am utilizat această tehnică pentru că în anumite moment anumite rezultate intermediare pot avea combinații diferite.
Cam atât pentru astăzi… Mai este o singură lecție pe site-ul Codility… dacă aveți alte colecții de probleme publice puteți să mi le oferiți în comentarii pentru a încerca abordarea lor. Eventual o resursă de probleme în română ar fi și mai fain.