În urmă cu ceva ani, unul din profesorii mei preferați (am mai mulți) ne povestea despre chinurile proiectării și implementării unui „motoraș” de repartizare a opțiunilor studenților sau candidaților pe anumite locuri în ordinea mediilor și preferințelor. Prima dată l-a făcut în SQL pentru admiterea la facultate. Ulterior l-a făcut în R. Recunosc că am privit oarecum cu invidie, pentru că în SQL chiar dacă am învățat destul de bine la master, nu am reușit să îl implementez, iar partea de R nu am înțeles-o prea bine, chiar dacă am mai cochetat din când în când.
Însă din momentul în care am început cercetarea profundă a programării funcționale în Excel, am reușit să fac lucruri pe care altă dată doar le visam și asta fără ajutorul generatoarelor de text, care sunt depășite de aceste metode. I-am mai spus lui ChatGPT că în Excel NU există FOR. El o ține pe a lui. Nu recomand! :)
Acest articol este un tribut pentru toți profesorii (unii actuali colegi ai mei) care m-au îndrumat și încurajat de-a lungul timpului să performez.
Fișierul de lucru poate fi accesat și descărcat de la adresa: AlocareOptiuni v1.xlsx. Acest fișier funcționează doar în versiunile Office 365 sau versiunile mai noi care suport funcții dinamice.
Proiecția problemei în Excel
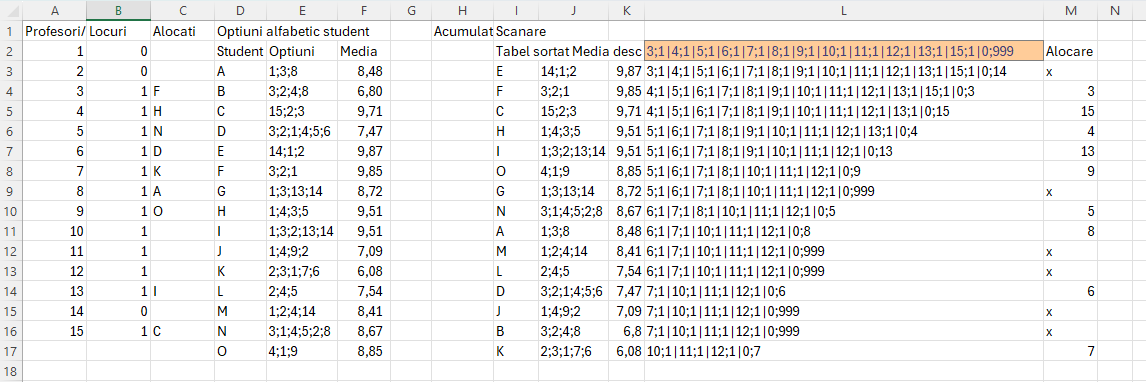
În exemplul prezentat în fișier, se presupune că avem o listă de profesori care au disponibile teme pentru lucrările de licență și un anumit număr de locuri pe fiecare temă. Ca să poată funcționa algoritmul propus, este esențial să codificăm fiecare temă în mod numeric. Numărul de locuri le specificăm tot numeric în dreptul codului fiecărei teme. Temele cu 0 locuri vor fi excluse automat din motorașul de repartizare.
Opțiunile studenților sunt prezentate ca un șir de opțiuni delimitate prin ; (punct și virgulă) în care fiecare număr este codul unei teme. Algoritmul aranjează sursa de date în ordine descrescătoare a mediilor după care face repartizarea după prima opțiune, apoi a doua dacă la prima opțiune nu mai sunt locuri și așa mai departe.
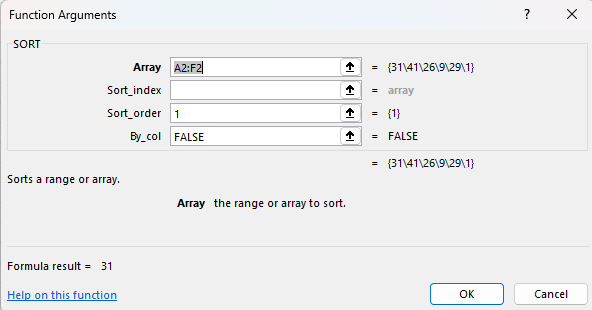
Funcția pe care o puteți întâlni și în fișierul Excel în celula K2 este:
în care:
locs este blocul de teme de la A2:B21 și care trebuie înlocuit în funcție cu propriile coduri
optiuni sunt numele studenților cu opțiunile lor și media. Există și posibilitatea de a aborda alocarea și în funcție de principiul primul venit primul servit. În acest caz, dacă ordinea este cea prezentată în foaia de calcul, trebuie să modificăm valorile de pe coloana G cu numere descrescătoare.
Pentru a reduce complexitatea și numărul de caractere, am definit la începutul formulei, 4 funcții recursive: _fCumulare(tab), _fDecumulare(acumulate), _fLast(x) și _fLastN(x) pe care le utilizez în _scan cu precădere și în result.
Explicam în articolele trecute că un SCAN() nu poate lucra cu tabele ci doar cu o singură valoare. Ca să pot scana totuși tabele întregi, am nevoie de a unifica aceste tabele în valori parsabile.
Prin cod se observă un 999 la linia 8, în _scan și apoi în result. Acest 999 mă ajută să determin dacă o opțiune este în afara numărului de locuri disponibile.
Complexitatea acelui SCAN() poate fi văzută într-o proiecție intermediară aici:
Valoarea de final a fiecărui șir intermediar (acumulatorul din SCAN) este o combinație de 0 și rezultatul prelucrării: 999 sau valoarea opțiunii care îndeplinește criteriile alocării pentru acel student.
În momentul în care am alocat un loc, ca să pot face scăderea lui din locurile rămase am apelat la scăderea a două matrici în variabila ramase (linia 19) care adună rezultatul decumulării acumulatorului curent din intro (linia 12) cu o matrice cu două coloane generată dinamic în funcție de numărul de linii rămase din intro.
Vizual această oprațiune de scădere a matricilor ar fi:
Această tehnică mi-a permis să am oricâte opțiuni din partea unui student și să le tratez pe toate în funcție de ce a mai rămas în acumulator.
Chinul cel mare nu a fost la SCAN ci la integrarea rezultatelor în aceeași formulă. În versiunile intermediare MAP() era soluția logică la calculul variabilei resut. Până la urmă l-am folosit, dar am lucrat doar cu șiruri fără reutilizare funcțiilor de Cumulare și Decumulare. Efectiv nu poți într-un MAP dintr-un LET să folosești rezultatul intermediar al lui SCAN pe care sa-l transformi din nou în tabelar, chiar dacă rezultatul în proiectezi ca valoare atomică cumulată.
În celula C2 pentru a calcula pentru fiecare temă studenții alocați am implementat un simplu TEXTJOIN() de filtrare. Formula din C2: =TEXTJOIN(„;”;;FILTER($K$2:$K$18;$L$2:$L$18=A2;””)). Trebuie să modificați adresele dacă aveți mai multe sau mai puține opțiuni.
Cam asta ar fi.. cazurile de aplicare pot fi diverse, important este să aranjam datele de intrare corect dacă dorim să utilizăm acest „motoraș” de repartizare.
Bun găsit cititorilor acestui blog. De curând mi-am asumat rolul de ambasador MECC pentru Universitatea Alexandru Ioan Cuza din Iași. Prin acest rol mi-am propus să popularizez competițiea mondială Microsoft Excel Colleciate Challenge organizată de University of Arizona împreună cu FMWC . Sponsorul principal este compania Microsoft.
Această competiție este destul de intensă, iar participarea studenților români lipsește cu desăvârșire, de aceea consider că acest demers este foarte important. Domeniile de studiu ale studenților sunt în special cele economice, de informatică, matematică și toate celelalte domenii care au în programa lor de pregătire colectare, manipulare și interpretare de date. Problemele pot fi rezolvate atât cu Excel clasic, Excel Modern cât și cu Python Anaconda integrat în Excel.
Detaliile despre organizare, înscriere, format sunt disponibile pe site-ul: https://mecc.college/
La competiție pot participa și elevii de liceu în anumite condiții documentate pe site. Pentru ei există o categorie de fișiere puțin mai simplă: Junior Varsity. Atenție la denumirea fișierelor.
Pe scurt, după înscriere, urmăriți calendarul competiției iar în momentul în care apar etapele de calificare veți primi un email. Competiția se derulează de obicei în zilele de weekend și se poate participa individual sau în echipe. Participarea este gratuită!
Pentru studenții de la UAIC, am creat o echipă de Teams în care vă puteți înscrie utilizând codul 5zx4gq8 Trebuie să deschideți Teams, Join or create team, Join team, Join a team with a codeși tastați codul apoi Add team. Acolo veți găsi resurse de pregătire off-line sau în comun. Ca să pot primi informările automat cu privire la rezultate rog studenții să se înregistreze la instituție cu numele: Alexandru Ioan Cuza University indiferent de facultate.
Pentru studenții de anul I, FEAA de la CIG Seria 1 care fac laboratoarele cu mine, vor primi bonificații la laborator pentru obținerea de punctaj la etapa din 20-23 februarie 2025 și sau 27-30 martie 2025.
Pentru prezentarea competiției am decis crearea unei întâlniri pe Teams cu acces public. Prima întâlnire va avea lor în data de 17.02.2025 de la 13:00 la 14:30.
Agenda
Prezentarea competiției
Înregistrare și acces la materiale
Prezentare model de caz (Ianuarie 2025 – Original autor Harry Gross)
Explicații instruire – 1. Text_Functions (autor Harry Seiders)
Resurse de învățare
Întâlnirea are setată o secțiune de Q/A. În funcție de interes, stabilim următoarele întâlniri și discuții.
Nu am idee cum s-ar traduce cel mai bine în limba română această metodă. Unii spun că ar fi metoda omidei alți autori metoda ferestrei glisante bidirecționale. Scopul meu este să rezolv în Excel problemele din această categorie, rezolvări care mi s-au părut relativ simple în Excel.
Denumirea vine de la modul în care algoritmul își extinde și retrage fereastra de procesare, similar cu modul în care o omida se mișcă – înaintează secvențial, dar își ajustează poziția astfel încât să acopere eficient o zonă, fără suprapuneri inutile.
În Excel operațiunile acestea le putem face prin indexarea unui vector în funcție de diferite poziții curente de căutare, adresabile prin variabilele R și C ale lui MAKEARRAY() sau cele 3 valori ale matricelor de triplete TripleG (denumire pe care o dau eu acestei tehnici descrise în mai multe ocazii).
Dar înainte de a începe să prezentăm…
Foarte puțină teorie
Pentru a secvenția un vector sau un tabel în Excel avem la dispoziție mai multe funcții, modul în care le utilizează fiecare dintre noi depinzând de experiență, inspirația de moment sau cunoașterea lor.
Principalele funcții pe care le adresez în această secțiune sunt: TAKE(), CHOOSECOOLS(), COOSEROWS(), DROP(), INDEX().
INDEX() în combinație cu MATCH() a fost mult timp considerat o alternativă la VLOOKUP(). Doar că această funcție poate face mult mai mult chiar dinainte de funcțiile dinamice, când artificiul suprem erau funcțiile CSE (Ctrl+Shift+Enter). Combinat cu SEQUENCE() în versiunile moderne de Excel nu mai este nevoie să introducem funcția cu CSE ci funcționează automat. Plus dinamica lui Sequence ne poate duce la soluții extraordinar de spectaculoase. Vezi exemplul din A14 unde aducem ultimele 3 numere din tabel de pe ultima coloană în ordine inversă.
Avantajul lui DROP și TAKE este că pot adresa atât linii cât și coloane prin parametrii 2 și 3. Coloanele și liniile pot fi adresate cu numere pozitive în ordinea coloanelor (1 prima coloana, 2 primele două coloane) cât și negative (-1 ultima linie/coloana, -2 ultimele două linii sau coloane). Choosecols sau Chooserows sunt oarecum mai precise pentru că adresează exact coloana sau linia specificată, dar pot fi și ele combinate cu SEQUENCE() pentru a adresa mai multe linii sau coloane. De exemplu în K6 putem face o optimizare cu sequence în forma: =CHOOSEROWS(COOSECOLS(vNumere;1); SEQUENCE(5;;2))
Personal consider că în cele mai multe cazuri INDEX() este de departe funcția câștigătoare, dar nu sunt de neglijat nici celelalte cazuri de utilizare.
Sortarea valorilor pe linie?!
Într-o zi una din firmele cu care lucrez pe partea de training privat de Excel mi-a trimis o agendă personalizată pentru un curs de Excel Avansat în care unul din puncte era sortarea valorilor pe linii. Eu când nu știu ceva, nu predau sau nu accept deloc clientul. Având în vedere că era totuși un client vechi și important am cerut clarificări… dar nu înainte de a mă uita pe internet dacă există așa ceva…
Ceea ce mi s-a confirmat și am găsit pe Internet mi s-a părut ceva simplist așa că am mers înainte. Dar cazul nu este deloc așa cum ar trebui.
Pentru versiunea manuală de sortare dacă vrei să faci sortarea pe linie:
Dacă vrei să sortezi valorile existente direct în tabel trebuie să parcurgi următorii pași:
Selectează rândul cu datele pe care vrei să le sortezi.
Mergi la „Home” sau „Data” → „Sort & Filter” → „Custom Sort”.
În fereastra de sortare, apasă pe „Options” și selectează „Sort left to right”.
Alege criteriul de sortare (ordine crescătoare sau descrescătoare) și apasă OK.
Având în vedere că în Excelul modern, operațiunile manuale sunt înlocuit cu funcții, operațiunea se poate realiza și prin funcția SORT() cu valoarea FALSE pentru parametrul 4.
Și totuși dacă am dori să sortăm toate valoarile crescător pe fiecare linie în parte?
Lucrurile nu mai sunt la fel de simple pentru că funcția sort nu mai funcționează așa cum ne-am aștepta. În Excel, SORT() este dedicat implicit valorilor de pe o coloană, iar ca să ducem o linie în coloană folosim TRANSPOSE().
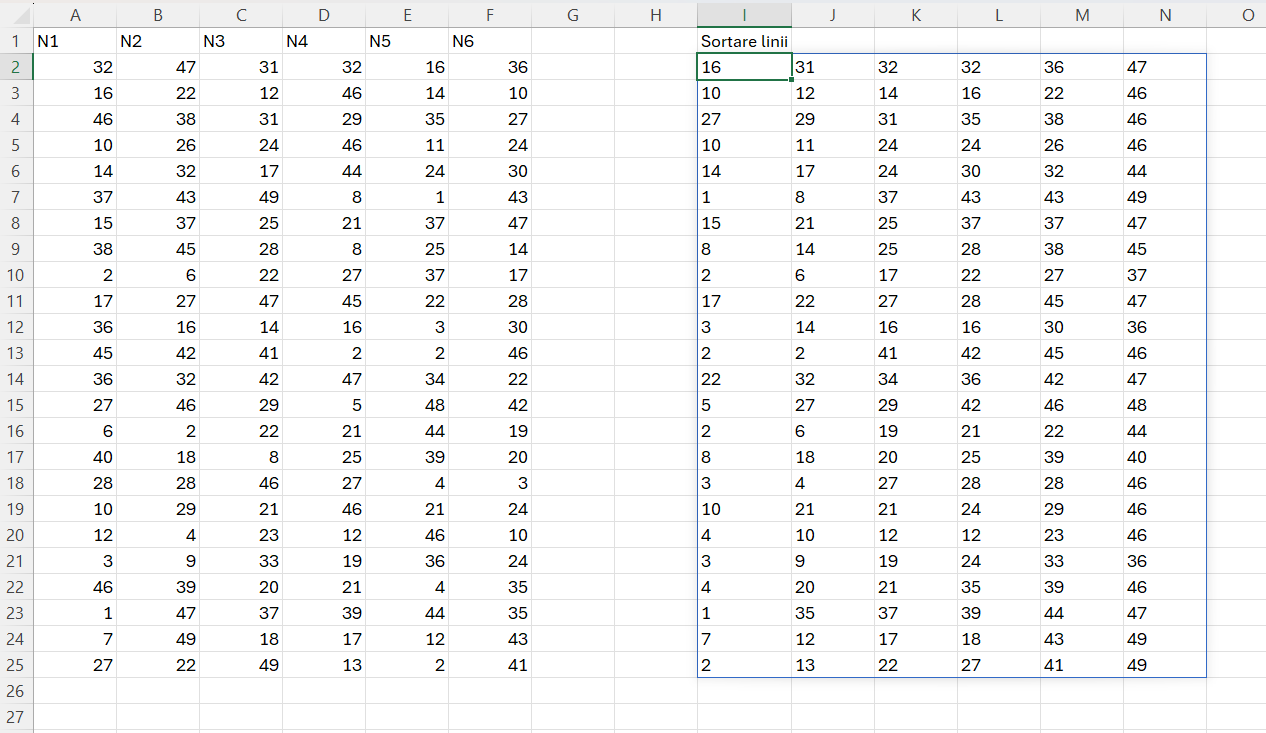
Exemplificare valori random:
Pentru această operațiune introduc în acest articol funcția _fSortRows() care are următorul corp:
arr – este blocul de numere generat aleator cu RADARRAY();
join – unește toate valorile de pe linie pentru a le putea parcurge linie cu linie cu MAP() din rez;
result – este rezultatul cu artificiul de splitare a blocurilor de valori pe linii și coloane.
Această parte am sintetizat-o și într-un scurt clip video.
Acestea fiind spuse, să trecem la rezolvarea problemelor:
Problema AbsDistinct
Problema AbsDistinct presupune determinarea numărului de valori distincte dintr-un array, luând în considerare doar valoarea absolută a fiecărui element.
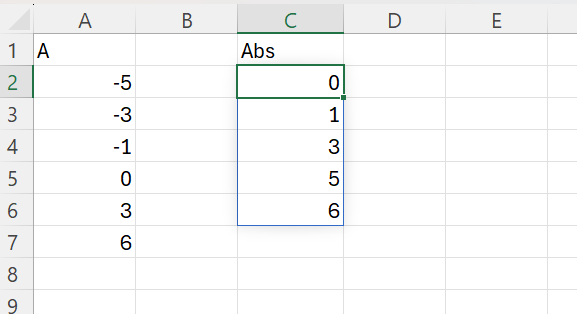
Exemplu Dacă avem următorul array sortat: -5,-3,-1,0,3,6 Valorile absolute sunt: 0,1,3,3,5,6 Valorile distincte sunt: 0, 1, 3, 5, 6 (5 valori distincte).
Rezolvarea este foarte simplă în Excel:
în C2 am utilizat formula: =SORT(UNIQUE(ABS(A2:A7)))
în care ABS calculează absolutul fiecărui număr din vectorul A, UNIQUE() determină toate valorile unice, iar SORT() le sortează ascendent.
Această metodă poate fi utilizată în cazul tranzacțiilor bursiere pentru a identifica variațiile unice absolute ale unei acțiuni într-o perioadă de timp.
Problema CountDistinctSlices
În cardrul acestei probleme avem un șir de numere (A) și vrem să determinăm câte sub-secvențe distincte (numite și slice-uri) pot fi formate, astfel încât toate elementele din fiecare sub-secvență să fie distincte.
Scopul problemei este să aflăm câte sub-secvențe (slice-uri) distincte există, astfel încât niciun număr dintr-un slice să nu se repete.
Rezolvarea problemei nu a fost chiar atât de simplă cum pare la final din cauză că nu am identificat de la început calea cea mai simplă de rezolvare, eu abordând matricial problema cu Makearray(). Doar că matricile nu rezolvă problema sau cel puțin nu am identificat calea corectă.
Rezultatul sugerat de cei de la Codility era dat de următoarele combinații unice: (0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2), (3, 3), (3, 4) and (4, 4) eu personal neînțelegând la început că slice (0,2) înseamnă valorile 3,4,5.
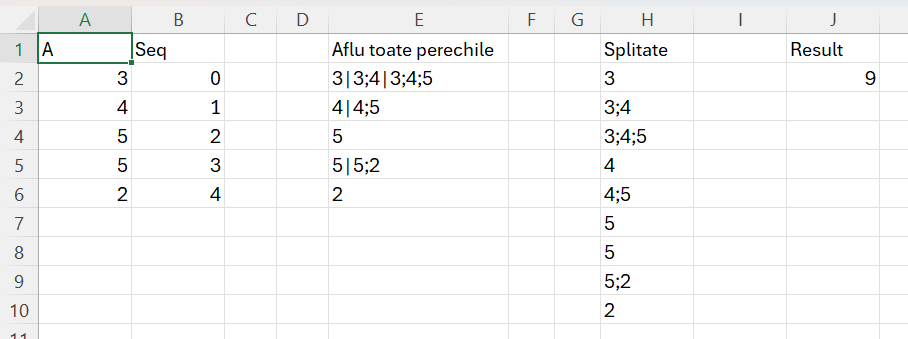
Ca să pot rezolva problema am introdus în E2 o formulă destul de abstractă pe care încercă să o explic:
Ca să pot scana blocul de la poziția 0, apoi de la poziția 1 și așa mai departe, a trebuit să definesc secvența din B2 pe care o parcurg cu MAP(). Apoi pentru fiecare poziție, returnez o combinație de valori de pe blocul A2:A6 pe care-l parcurg cu SCAN(). Partea frumoasă a acestei construcții este dată de faptul că în acumulatorul a introduc întotdeauna valorile în ordinea lor, ceea ce-mi permite să le iau cu acel TAKE() pentru a-l putea compara cu valoarea curentă V ca să identific dacă valorile sunt egale. Scan-ul funcționează la început pentru valoarea 0 a vectorului din B2#. Apoi map-ul duce Scanul mai jos pentru restul de slices.
În H2 folosesc artificiul de splitare: =TEXTSPLIT(TEXTJOIN(„|”;;E2#);;”|”)
Integrate toate operațiunile într-o singură formulă ar arăta:
în care în variabila prerechi calculez acel MAP cu SCAN integrat.
O variantă oarecum diferită a acestei soluții este să oprim SCAN-ul în momentul în care o valoare din A se repetă anterior. Exemplificare:
În acest context când în prima rundă de scanare apare varianta 3 care este deja mai sus, se oprește scan și trece la secvența următoare. Pentru aceasta folosesc o funcție ușor diferită dar cu aceeași logică.
În prima variantă folosesc doar ultima valoare din acumulatorul a iar în varianta 2 compar toate valorile din acumulator cu valoarea curentă. De reținut aici că nu putem utiliza un COUNTIF() într-un SCAN așa că a trebuit să introduc artificiul de a compara oricare valoare din A cu V și transformarea în valori 0,1.
Problema CountTriangles
Problema CountTriangles se referă la identificarea tripletelor dintr-un șir de numere care pot forma triunghiuri valide conform inegalității triunghiului.
Inegalitatea triunghiului afirmă că, pentru trei laturi a,b,c ale unui triunghi, trebuie să se respecte condiția: a+b>c , b+c>a, c+a>b Într-un șir sortat, regula devine mai simplă: dacă avem trei elemente A[i],A[j],A[k] unde i<j<k , triunghiul este valid doar dacă: A[i]+A[j]>A[k].
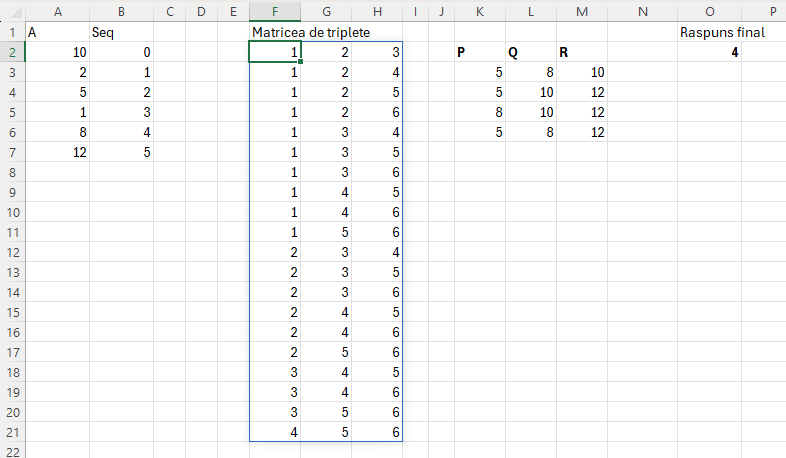
Ca să putem compara oricare 3 elemente dintr-un vector avem nevoie de matricea de triplete introdusă în articolul Modele de algoritmi in #Excel – Sorting (6). De asemenea, problema triunghiurilor a mai fost tratată în articolul menționat la Problema Triangle. De asemenea, a fost descrisă puțin mai pe larg în articolul Programarea funcțională în Excel Modern din pinmagazine.ro una din ultimele reviste de IT, pe care le cunosc eu, disponibilă și offline.
Scopul matricei de triplete este de a genera toate combinațiile unice de câte 3 valori corespunzătoare indexului valorilor pozițiilor unui vector A cu începere de la 1. În articolul din PIN Magazine scriam că această matrice este echivalentului unui triplu FOR din programare. Reamintesc funcția de generare a matricei de indecsi unici.
Această funcție este optimizată în raport cu numărul de elemente din șirul din R1 în cazul acesta pentru că suportă până la 185 de elemente în șir față de 101 în varianta din articolul 6.
Proiecție problemă în Excel
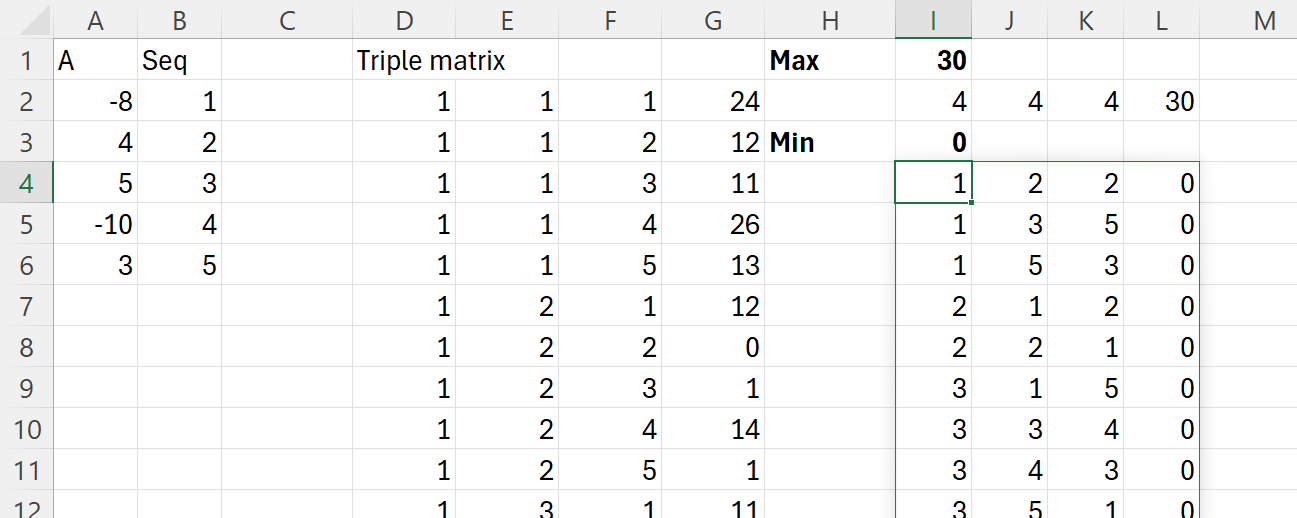
Formula din K3 este bazată pe o variantă a articolului 6 și este:
În care în prima parte se generează matricea de căutare, după care prin funcția recursivă fReqv se indexează vectorul de valori A cu scopul de a determina inegalitățile de tipul a+b>c solicitate de problemă. În felul acesta determinăm că anumite combinații de numere pot reprezenta triunghiuri din punct de vedere geometric.
Problema MinAbsSumOfTwo
Având în vedere că este o problemă cu două valori dintr-un vector care trebuie comparate, soluția optimă în Excel este utilizarea unui MAKEARRAY().
Problema constă într-un vector de numere a cător sumă în format aboslut trebuie să fie cea mai mică. Formal, dacă avem un array A de dimensiune N, trebuie să determinăm: min(|A[i]+A[j]|) unde 0≤i≤j<N.
în care matricea generată cu MAKEARRAY indexează vectorul arr pentru fiecare combinație de linie și coloană.
O variație a acestei probleme care nu există pe Codility este să determin mimimul sau maximul absolut a trei valori din vector. Această problemî în Excel ar arăta:
în care am utilizat din nou matricea de triplete, dar de data aceasta cu scopul de a păstra toate valorile posibile în matrice nu doar valorile unice.






")