Acest articol este o continuare a seriei de articole cu propunere de rezolvare a algoritmilor clasici în Microsoft Excel ediția 365. Probelemele de astăzi fac parte din algoritmii Leader descriși la adresa: https://app.codility.com/programmers/lessons/8-leader/
Algoritmul Leader se referă la identificarea unui element dintr-o secvență de valori care apare mai mult de jumătate din numărul total al elementelor din acea secvență. Acest element este denumit „leader” sau „dominator”. Problema se poate formula astfel: având un vector de dimensiune N, să se găsească elementul care apare de cel puțin N/2 + 1 ori, dacă există unul. În mod programatic se recomandă rezolvarea acestor tipuri de probleme cu algoritmul Boyer-Moore majority vote.
Doar că Excelul este puțin diferit și este mai greu de adaptat la rezolvările clasice care implică secvențe FOR. Alternative există și unele din ele sunt foarte interesante. Dar să începem cu:
Un pic de teorie
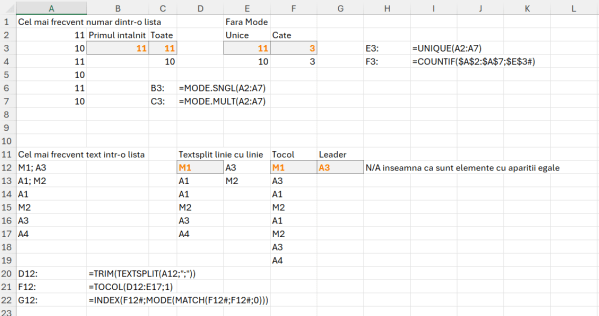
În mod clasic dacă am avea un șir de numere sau valori ar trebui să identificăm unicele, apoi să facem un countif pe blocul inițial.
De exemplu în E3: folosim funcția UNIQUE() pentru a calcula elementele unice din vectorul A2:A7, după care utilizăm un COUNTIF() dinamic pe vector după rezultatul din E3#. În felul acesta determinăm numărul de apariții a fiecărui element. Există și o variantă puțin diferită, de a folosi funcția FREQUENCY() în forma: =FREQUENCY(A2:A7; UNIQUE(A2:A7)) dar ea determină doar numărul de apariții a fiecărui element, în cazul nostru 3/3.
În Excel în schimb există o altă funcție MODE cu două variante: SNGL sau MULT. MODE.SNGL() extrage dintr-un șir de valori cea prima cea mai frecventă valoare. În exemplu nostru (B3) avem două valori care au același număr de apariții, ceea ce înseamnă că va afișa doar prima valoare întâlnită în vectorul de căutare. MODE.MULT() extrage cele mai frecvente numere, în cazul în care avem egalitate la numărul de apariții le va afișa pe ambele. În cazul în care nu avem nici un leader, funcția MODE va afișa eroarea #N/A.
O abordare interesantă este în schimb la text, pentru că MODE.MULT() funcționează doar la valori numerice. În modelul propus în imaginea anterioară, ca să putem determina leaderul folosim un MODE dar pentru un MATCH care extrage pentru fiecare valoare întâlnită poziția inițială a sa. După care pe același șir extragem valoare pentru cea mai mare valoare. MODE() în formatul clasic încă este funcțional și compatibil în Excel 365.
Problema Dominator
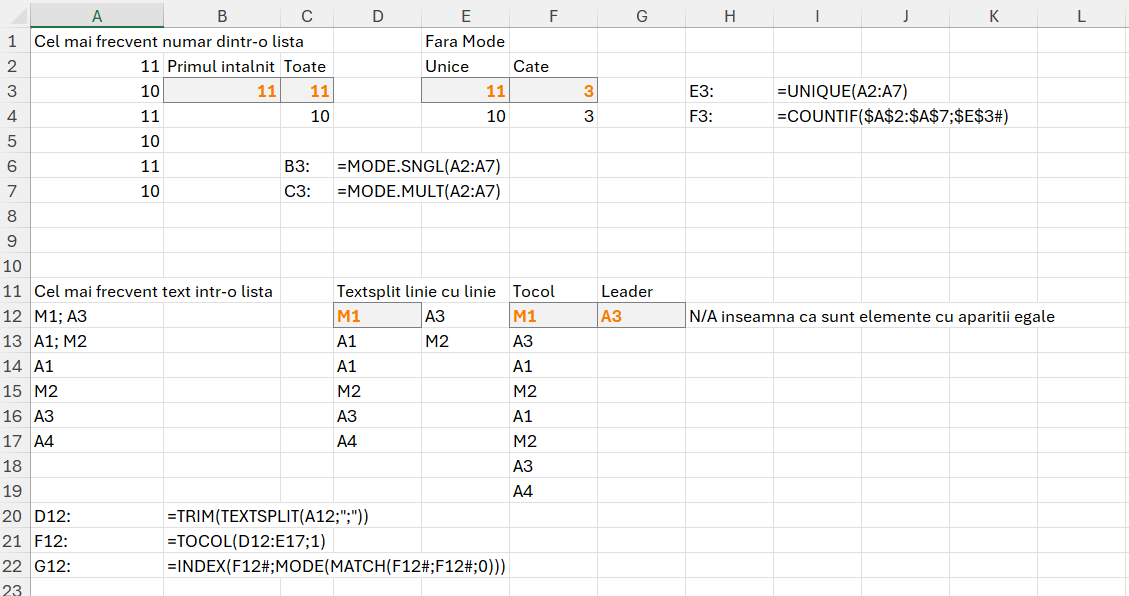
În problema Dominator ni se cere să determinăm care este numărul dintr-un vector care apare de mai mult de jumătate din lungimea vectorului. De asemenea, se poate solicita extragerea pozițiilor din vector în cazul în care avem un număr Dominator.
Propunerea de rezvare pas cu pas:
Ca să determin Leader-ul este simplu să folosim un MODE.MULT() în E3, dar ca să determinăm dacă este dominiator avem nevoie de numărul de elemente din vector (B2), valoarea de dominare care este numărul de elemente împărțit la 2 (C2), numărul de apariții (F2), verificarea că Leaderul este dominator (G2), iar dacă dorim să extragem pozițiile în vector va trebui să folosim o secvență cu start de la 0 (D2) pe care să o filtrăm după pentru cazurile în care A este egal cu Leader care devine dominator.
Unificat într-o singură funcție cu LET() aceasta ar fi:
În funcție am două verificări: verifi și verifii. În verifi verific dacă am un singur rezultat sau mai multe. În cazul în care sunt returnate mai multe valori prin MODE.MULT atunci nu avem un dominator ci mai mulți Leaderi. În rest logica funcției este descrisă în secțiunea de rezolvare pas cu pas.
Problema EquiLeader
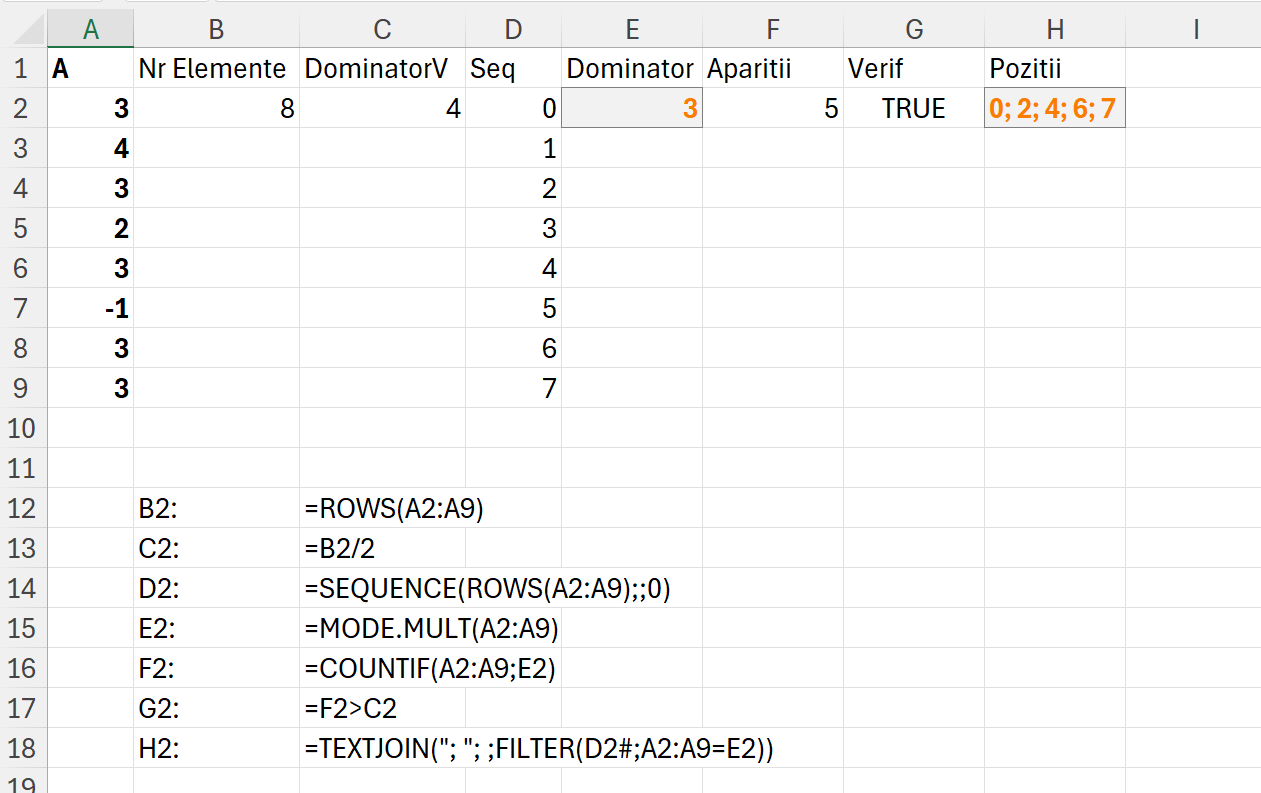
Aceasta este o versiune mai complexă a problemei Dominator pentru că presupune compararea dinamică a leaderilor pe două secțiuni ale aceluiași vector. În această problemă, trebuie să determinăm numărul de poziții dintr-un array unde liderii celor două sub-secvențe (stânga/sus și dreapta/jos) sunt identici. Concret: Având un array A de dimensiune N, o poziție S este un echileader dacă liderul sub-secvenței A[0…S] este același cu liderul sub-secvenței A[S+1…N-1]. Trebuie să găsim numărul total de astfel de poziții în array.
În care pe coloana C determinăm dacă în poziția curentă comparată cu celelaltă secțiune avem egalitate de Dominatori, iar pe coloana D afișăm combinațiile de pe secvența de pe B. Funcția de pe C și D este aceeași cu specificarea că rezultatul final este afișat diferit.
Cheia în rezolvarea problemei, este funcția freq care este utilizată recursiv în MAP-ul care calculeaza valoarea pp și dp. freq este de fapt funcția de determinare a dominatorului din problema Dominator, dar care este generalizată pentru a prelua parametrul de intrare a, care se transformă în x în LET() și calculează dominatorul pe subvectorul determinat în pp și dp de index-ul dinamic.
ppa și dpa se folosesc pentru a extrage valoarea din secvență pentru a afișa pozițiile din vector și secțiunile unde întâlnim dominatori egali.
Rezultatul 2 al funcției este numărul de segmente de pe vector care înreplinesc condiția de egalitate între dominatori.
Ca aplicabilitate practică putem să ne gândim la analize de piață pentru a identifica dacă pe diferite segmente sau intervale de timp există un brand dominant.
În acest articol voi propune diferite metode de rezolvare a problemelor clasice de algoritmică cu focus pe zona de stive și cozi, probabil cele mai utilizate concepte în programare și mai ales în lucrul cu datele. Cum am mai spus cu diferite ocazii, Excelul nu ar trebui să fie un instrument pentru colectarea, stocarea și gestionarea unui volum mare de date, ci mai mult un instrument de analiză și rafinare rapidă a unor seturi restrânse de date. Da, poate face asta dar uneori nu foarte eficient, sau efortul este mai mare decât dacă ai utiliza alte instrumente.
Excelul se dezvoltă rapid datorită numărului mare de utilizatori din variate domenii de activitate, dar și creativității acestora. La ora actuală vorbim despre mai multe metode de rezolvare a diferitelor probleme în Excel dintre care amintim:
Excel clasic
utilizarea formulelor și funcțiilor clasice
utilizarea unor instrumente clasice de rezolvare probleme: Pivot table, Data table, Solver
utilizarea VBA, tehnologie pe care eu personal o consider depășită
Excel modern
utilizarea Power Pivot și Power Query (limbaj m)
utilizarea DAX
utilizarea Automate (un înlocuitor modern al VBA, dar încă la început de drum)
utilizarea Dynamic arrays.
Ceea ce vă propun eu prin seria de articole despre algoritmi este utilizarea Dynamic arrays, parte componentă a Excel modern. Sunt convins că aceste probleme se pot rezolva și cu celelalte metode.
Marele dezavantaj al funcțiilor actuale care lucrează cu dynamic arrays este acela că nu au integrată funcția de prelucrare iterativă for din programare clasică.
Pentru că toți învățăm de la cineva, citez și eu în acest articol, câteva metode de a rezolva diferite probleme de iterații în excel în locul for-ului propuse de Diarmuid Early, vicecampion modial Excel eSports, în videoclipul Write Excel firmulas like a programmer.
Câteva concepte teoretice
Așa cum menționam în Excel nu avem for. Cu ce facem iterațiile atunci? Nu putem face iterații adevărate dar putem simula iterațiile prin utilizarea unor combinații de funcții Sequence combinate cu scan, map, reduce, byrow, bycol.
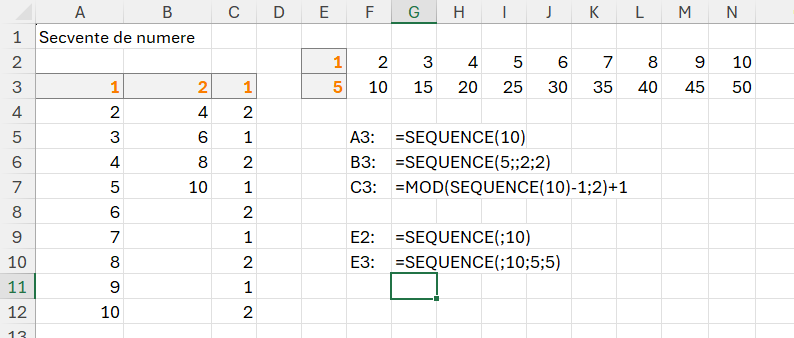
În imagine câteva exemple de utilizare a funcției sequence():
Parametrii lui sequence sunt:
Rows: numărul de linii pe care dorim să le generăm (exemplu în A3 avem 10 linii)
Columns: numărul de coloane pe care dorim să le generăm (exemplu în E2 primul parametru rows nu este completat și formula începe direct cu separatorul ; (punct și virgulă) echivalentul , (virgulă) din versiunea în engleză.
Start: numărul de la care să pornească numerotarea (exemplu în B3, generăm 5 numere pe o coloană (rows) pornind de la valoarea 2. În E3, pornim de la 5)
Step: pasul de creștere, implicit 1.
În C3 combin un sequence care generează 10 numere cu un mod prin artificiul -1/+1 pentru a putea obține 10 numere în formatul dat.
Cele mai utilizate funcții de scanare a vector sunt prezentate în imagine:
SCAN și REDUCE au aceeași sintaxă, numai că scan calculează pentru fiecare element din vector, adică ajungem pas cu pas la valoarea finală, rezultatul fiind un array de valori, pe când REDUCE calculează direct valoarea finală. Parametrii celor două funcții sunt:
valoarea inițială de la care pornim, în cazul meu 0 în ambele cazuri (B16 și C16);
vectorul de scanat, în cazul meu A16#;
funcția lambda care se ocupă cu modul de calcul efectiv. Cheia în această funcție este că are doi parametri: a și v în această ordine. A este valoarea acumulată prin operațiunile returnată de lambda până la V, valoarea curentă.
Foarte important de știut: SCAN nu lucrează cu tabele de date și nici nu returnează tabele de date ci un singur vector. Dacă dorim să lucrăm totuși cu tabele, atunci putem reduce întreg tabelul la un vectori de valori prin concatenare după care să lucrăm cu artificiul prezentat data trecută de splitare în linii și coloane:
MAP este o funcție la fel de interesantă, care are doar 2 parametri: vectorul de parcurs și funcția lambda pentru calcule care are ca parametru de intrare valoarea curentă (v). Da, putem face cu un MAP ce facem cu un SCAN, vezi formula din E16, doar că într-un mod oarecum mai complicat. Personal consider că scan este recomandat, dar uneori se complică problemele când dorești să lucrezi cu valoarea anterioară nu cu acumulatorul. Veți vedea mai jos.
Combinând între ele sequence cu scan putem emula operațiuni for în Excel, chiar dacă unele variante cu stop la o anumită condiție, încă nu știu cum să le rezolv. :)
În continuarea articolului voi prezenta câteva propuneri de rezolvare a problemelor de pe Codility.
Problema Brackets
Problema „Brackets” face parte din categoria algoritmilor de tip Stacks and Queues și este folosită pentru a verifica corectitudinea unui șir de paranteze. Aceasta este o problemă clasică de validare a echilibrului și închiderii corecte a parantezelor într-un șir.
Enunțul problemei: Un șir de caractere conține următoarele tipuri de paranteze: (), {}, []. Trebuie să determinăm dacă șirul de paranteze este corect închis și echilibrat. Un șir de paranteze este considerat corect dacă:
Fiecare paranteză deschisă are o paranteză corespunzătoare închisă de același tip.
Parantezele închise sunt în ordinea corectă.
Exemplu (), ([]{}), {[()()]} sunt șiruri corecte. (], ([)], {{{{ sunt șiruri incorecte.
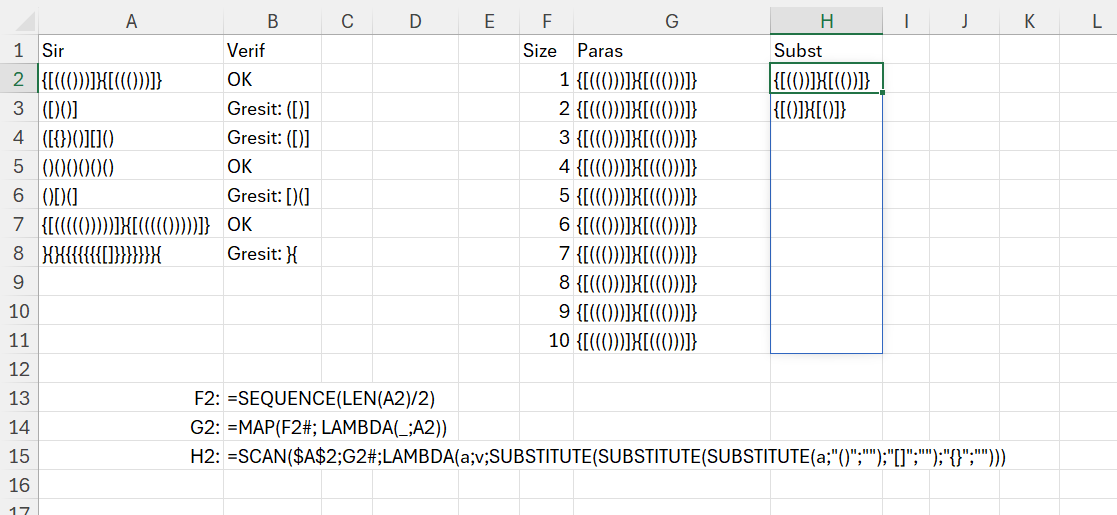
Modelul este destul de bizar, am încercat diferite abordări, clasic prin descompunerea într-un vector… dar fără succes, iar dacă cumva riscați să încercați o rezolvare cu ChatGPT… treaba e tristă rău. :) Doar încercați…
Propunerea mea de rezolvare după ceva abordări matematizate și care mai de care mai alambicate:
În rezolvarea problemei am pornit de la generarea unei secvențe de jumătate din lungimea totală a șirului de paranteze. Practic ele vin în perechi deschis, închis deci nu ar trebui să existe mai multe rulări. După care pentru a putea scana și substitui perechile deschis închis ca să vedem dacă rămâne una închisă eronat sau neînchisă, am replicat șirul de paranteze de dimensiunea secvenței generate prin maparea șirului de secvență și utilizarea unei fake Lambda, în care parametrul de intrare, în loc de V l-am înlocuit cu _ (undescore) pentru că nu-l folosesc la nimic.
În scanul din H2, care pornește de la șirul inițial din A2 și verifică pe G2 (care este un V identic), am substituit pe rand parantezele din valoarea acumulată. Ceea ce înseamnă că el de fapt face o substituție repetitivă pentru câte rulări i-am specificat prin Size. Rezolvarea nu este optimă din punct de vedere algoritmic pentru că în fiecare pas execut un număr determinat de la început de pași. Așa cum specificam în partea de teorie nu putem să oprim execuția la îndeplinirea unei condiții ci executăm în continuare după un număr de pași prestabiliți.
În formula pentru o singură celulă am vrut să integrez și secvența de paranteze care nu se potrivește.
În care în ultima parte am preluat ultima valoare a lui Scan care reprezintă parantezele care nu se potrivesc.
Având în vedere că sunt funcția propusă se aplică la toate tipurile de paranteze, aceeași soluție funcționează și pentru Problema Nesting de pe Codility.
Care este aplicabilitatea acestui tip de problemă?
Un pic forțat, un model de aplicabilitate ar fi acela de evaluare a unei secvențe de cod JSON, pentru a verifica dacă este valid din punct de vedere al parantezelor.
În același exemplu, în B11 am verificat și dacă ghilimelele sunt deschise și închise corect.
De asemenea, cred că putem defini și alte simboluri pe post de închidere / deschidere care ar putea fi verificate.
Problema Fish
Problema în care peștele cel mare îl mănăncă pe cel mai mic… mi-a dat cele mai dureroase bătăi de cap până acum. De ce? Pentru că trebuie să parcurgi un tabel cu două coloane de un număr necunoscut de ori.
Descrierea Problemei: Avem un râu în care n pești înoată în direcții opuse. Fiecare pește este descris de două atribute:
Un număr întreg care reprezintă mărimea peștelui. (A)
O direcție care poate fi 0 (înoată în amonte) sau 1 (înoată în aval). (B)
Peștii din amonte și aval își urmează cursul până când se întâlnesc. Atunci când doi pești se întâlnesc: Dacă peștele din amonte (0) este mai mic decât peștele din aval (1), peștele din amonte este mâncat. Dacă peștele din aval (1) este mai mic decât peștele din amonte (0), peștele din aval este mâncat. Dacă cei doi pești au aceeași mărime, peștele din aval (1) va mânca peștele din amonte (0).
Scopul problemei este să determinăm câți pești vor supraviețui după ce toți peștii care se pot întâlni și mânca au făcut acest lucru.
Propunere de rezolvare:
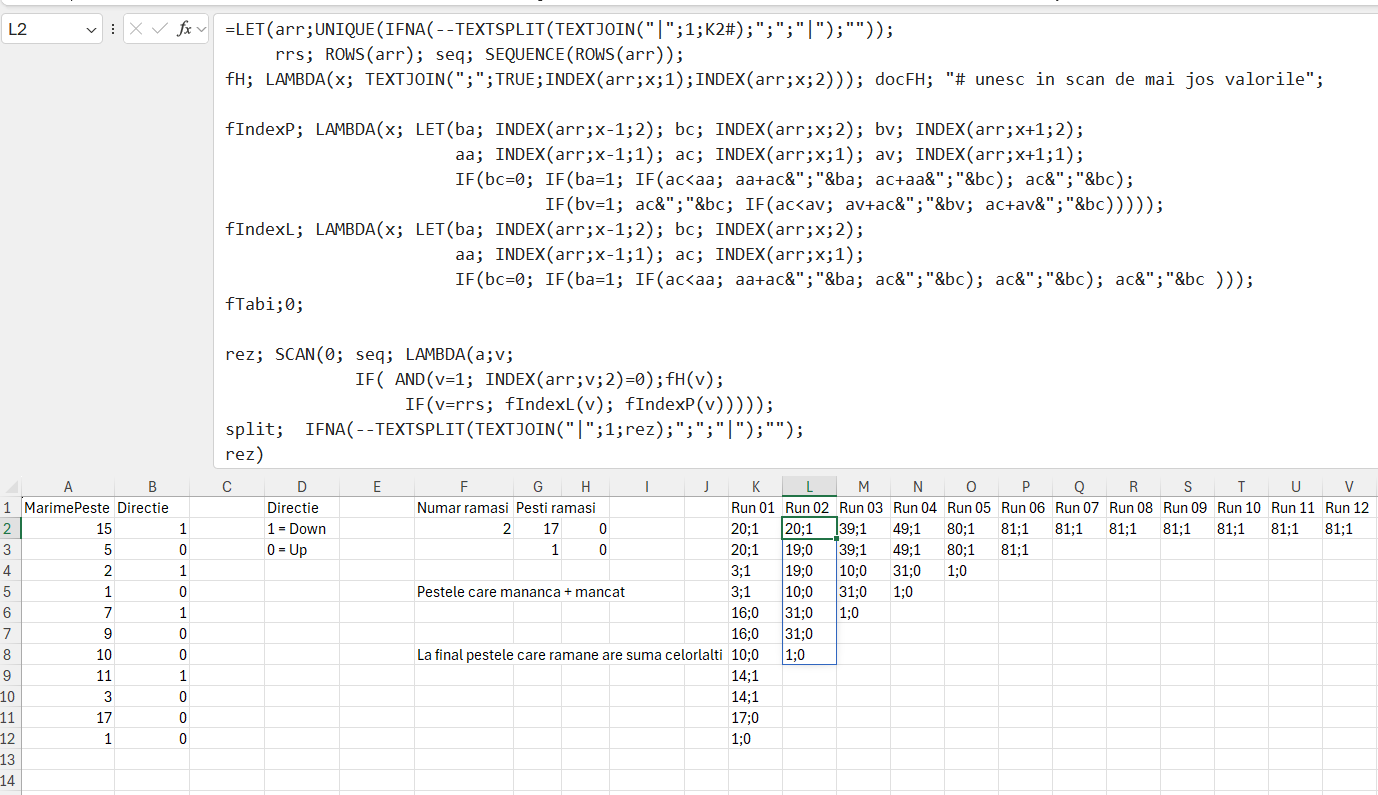
Ca să pot rezolva această problemă mi-am dat seama după mult timp că cea mai bună abordare este cu SCAN și căutări permanente și comparare cu valoarea anterioară sau valoarea următoare în funcție de direcția în care se mișcă peștele. Ca să ajung la funcția din G2, am trecut prin mai multe variante, una intermediară este acea a rulărilor care încep cu coloana K în care input pentru Run 01 este o concatenare a tabelului, iar pentru Run 02 încolo este rezultatul anterior. Aici a fost de fapt cheia: cum folosești un tabel ca un input recursiv?!
Rezultatul final este stocat în variabila rezfin care folosește o funcție REDUCE pe baza seqc variabilă ce definește o secvență pe coloane de numărul de elemente supuse analizei. Aici este problema de optimizare pe care nu am reușit să o rezolv în așa fel încât să determin optimul de rulări. În REDUCE folosesc funcția recursivă fscani cu parametrul de intrare ari dacă suntem la primul element din vector (v=1) sau a, dacă suntem la următoarele valori.
fscani este compus la rândul său din din mai multe funcții:
fH – utilizată pentru a concatena valorile celor două coloane de pe poziția 1, începutul scanului;
fIndexP – utilizată pentru a concatena valorile de dinainte sau de după înregistrarea curentă în funcție de 1/0 sau dimensiune, în care prin Index aducem valoarea dimensiunii peștelui: anterioară (aa), curentă (ac) sau următoare (av) și valoarea 0/1 specifică deplasării: ba – direcția de deplasare a peștelui anterior, bc, direcția peștelui curent și bv, valoarea peștelui viitor.
fIndexL – funcție derivată din fIndexP dar pe care o utilizez doar la ultimul element din vector. Aici ar fi mers o optimizare în fIndexP pentru a verifica cazul de eroare în cazul în care nu există valori viitoare.
Rezultatul final al funcției fscani este stocat în variabila rez care este de fapt un alt scan pe secvența inițială și aplică cele 3 funcții pe intervalul 1…n.
O variantă de implementare puțin diferită a acestui algoritm mi-a fost inspirată de un joc de pe telefoanele mobile, în care peștele mai mare care-l mănâncă pe cel mai mic acumulează punctele acestuia, spre final peștele acumulând majoritatea punctelor puse în joc.
Diferența față de funcția anterioară este că la indexare în momentul în care stabilesc peștele câștigător prin IF-ul din fIndexP în loc să afișez doar valoarea câștigătorului, adun la acesta valoarea celui care a fost mâncat.
Ca aplicabilitate practică a acestui algoritm mă gândesc în general la prioritizarea unor cozi de așteptare și apariția unui eveniment nou sau schimbarea priorității anumitor elemente. Cred că la managementul incidentelor putem utiliza prioritizare pentru a vedea care incident se va rezolva primul sau la portofoliile de investiții sau acțiuni pentru a determina care acțiuni merită vândute și ce trebuie achiziționat pentru maximizarea portofoliului.
Dincolo de toate Fish a fost pentru mine una din cele mai mari provocări tehnice de până acum. Clar, recomand metode programatice dar am demonstrat că se poate și în Excel.
Problema StoneWall
Descrierea problemei: Dându-se o secvență de înălțimi care reprezintă ziduri, trebuie să determinăm numărul minim de blocuri necesare pentru a construi aceste ziduri. Fiecare bloc are aceeași lățime și poate fi plasat în moduri diferite, dar trebuie să acopere întreaga înălțime specificată pentru fiecare zid, iar blocurile pot fi plasate unul peste altul.
Logica rezolvării problemei Să considerăm șirul de înălțimi H = [8, 8, 5, 7, 9, 8, 7, 4, 8].
8: Adaugă 8 în stivă. (stiva: [8]) 8: Este deja 8 în stivă, nu facem nimic. (stiva: [8]) 5: 5 este mai mic decât 8, eliminăm 8 din stivă. Adăugăm 5. (stiva: [5]) 7: 7 este mai mare decât 5, adăugăm 7. (stiva: [5, 7]) 9: 9 este mai mare decât 7, adăugăm 9. (stiva: [5, 7, 9]) 8: 8 este mai mic decât 9, eliminăm 9 din stivă. Adăugăm 8. (stiva: [5, 7, 8]) 7: 7 este mai mic decât 8, eliminăm 8 din stivă. (stiva: [5, 7]) 4: 4 este mai mic decât 7, eliminăm 7 și 5 din stivă. Adăugăm 4. (stiva: [4]) 8: 8 este mai mare decât 4, adăugăm 8. (stiva: [4, 8])
Total add-uri: 7
Propunere de rezolvare
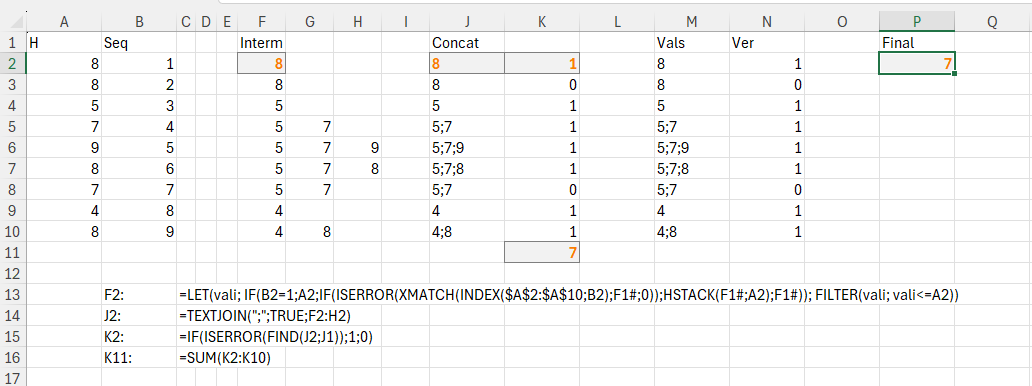
În prima parte (formulele afișate) am setat modelul problemei care la bază folosește un filtru dinamic pe poziția curentă (valoarea din B2) din vectorul H. Funcția din F2 este copiată apoi în jos. Vali este de fapt valoarea rezultată anterior, ceea ce ne duce cu gândul la o rezolvare integrată la acumulatorul dintr-un scan.
Valorile Iterm sunt apoi concatenate în J2, iar cu find-ul din K2, determin dacă există (1) adăugiri sau nu (0).
În P2 am stocat varianta finală integrată al cărei cod este:
Am revenit cu o propunere de rezolvare în Excel, din seria algoritmilor clasici. Doar nu credeați că am renunțat! :) Scuze dacă mai scriu greșit anumite cuvinte sau virgule… din viteză pentru a nu pierde idea. Dacă aveți observații sau comentarii, rog folosiți secțiunea dedicată.
În acest articol voi propune diferite metode de rezolvare a problemelor din categoria algoritmilor Prefix Sums, cunoscuți și sub numele de Scan, Cumulative Sum sau Inclusive Scan, se referă la o serie de metode eficiente pentru calcularea sumelor prefixelor unei secvențe de numere. Prefixul unei secvențe este definit ca suma elementelor din secvență până la un anumit punct.
Algoritmii Prefix Sums sunt utilizați frecvent în diverse domenii ale informaticii, cum ar fi:
Procesare secvențială: Algoritmii Prefix Sums pot fi utilizați pentru a calcula rapid sumele prefixelor unei secvențe de numere, ceea ce este util pentru diverse operații de procesare secvențială, cum ar fi căutarea binară, intervale de sume, și detectarea de elemente repetitive.
Baze de date: Algoritmii Prefix Sums pot fi utilizați pentru a implementa eficient indexuri de rang, care permit determinarea rapidă a numărului de elemente dintr-o secvență care sunt mai mici sau egale cu o anumită valoare.
Algoritmi de căutare: Algoritmii Prefix Sums pot fi utilizați pentru a accelera algoritmii de căutare, cum ar fi căutarea binară, prin precalcularea sumelor prefixelor.
Principiul de bază:
Ideea centrală a algoritmilor Prefix Sums este de a stoca o secvență suplimentară de numere numită „prefix sum array”. Această secvență conține suma elementelor din secvența originală până la un anumit punct. De exemplu, dacă secvența originală este [1, 2, 3, 4, 5], atunci prefix sum array-ul ar fi [1, 3, 6, 10, 15].
Odată ce prefix sum array-ul este calculat, se pot calcula sumele prefixelor oricărui interval din secvența originală cu o singură operație de scădere. De exemplu, pentru a calcula suma elementelor de la indicele 2 la indicele 4 (inclusiv), se calculează prefix sum array[4] – prefix sum array[1] = 15 – 3 = 12.
În Excel există o serie de funcții care ne ajută să implementăm nativ algoritmul, doar că problemele expuse sunt mai complexe pentru a putea fi rezolvate doar cu funcția SCAN().
În imagine este prezentat un exemplu prin care putem utiliza funcția SCAN pentru a determina suma elementelor de pe un array cu SCAN() sau suma tuturor elementelor dintr-un vector. Există mai multe metode și funcții pe care le putem utiliza pentru a aduce date de la o poziție la altă poziție a unui vector: OFFSET(), DROP(), INDEX().
În funcția =SCAN(0;A2:A9;LAMBDA(a;v;a+v)) scanăm vectorul A2:A9 și aplicăm funcția LAMBDA() în care avem parametrii a – acumulator și v – value (cu referire la valoarea de pe linia curentă). În acest exemplu adunăm cele două valori, pe linia următoare, a va aduna la suma de pana acum suma valorii curente (v).
În același fel funcționează și REDUCE() doar că în loc să calculeze pentru fiecare valoare a vectorului, aplică funcția fiecărui element din vector.
Ca să putem elabora un vector dinamic pentru prefix sums avem nevoie de o poziție de start și de final din șir. În celulele D4, E4, F4, G4 am prezentat diferite funcții care pornesc de la același start și au același număr de celule de extras (3). Diferența între funcții este că Offset() pornește de la 0 în abordarea unui bloc de celule la fel cu DROP().
Problema PassingCars este o problemă clasică de algoritmică care se referă la calcularea numărului de perechi de mașini care se depășesc reciproc pe o șosea cu o singură bandă. Mașinile se deplasează în ambele direcții și pot depăși alte mașini mai lente. Problema constă în determinarea numărului de perechi de mașini care se depășesc reciproc într-un anumit interval de timp sau pe o anumită porțiune de drum.
În propunerea de rezolvare, ca să înțeleg modul de abordare al problemei în vederea determinării numărului de perechi, am dus șirul în 2D F2xG1 după care am aplicat o combinație de funcții (I3) pentru a calcula minimul între linii și coloane. În funcție există un hardcode (7 de la numărul coloanei și 2 de la numărul de linii) dar este și problema că returnează și o combinație eronată, perechea 1-2 care nu este corectă.
În zona F9 – M14 am schimbat modul de implementare, transformând șirul în direcția Est (G10) prin splitarea șirului din B2. Apoi în coloana Start (F10) determin o secvență de numere de la 0 pe baza numărului de linii a vectorului G10#. Pentru a reprezenta ordinea mașinilor dinspre Vest (H10) ca să le pot compara cu cele care vin din Est am folosit sortarea descendentă (-1) a valorilor de pe Est (G10#) după cele de pe Start (F10). Pentru a determina punctul final am inversat șirul start prin sortarea descendentă (-1). Conform cerințelor problemei, ne interesează când mașinile care vin din Est ( valoarea 0) se intersectează cu cele care vin din Vest (valoarea 1). Ca să pot realiza acest lucru a trebuit să fac o filtrare a valorilor de pe coloana Start cu cele de pe coloana Est. Din cauza faptului că șirul de Start începe de la 0 iar eu intenționez să folosesc funcția de căutare INDEX() a trebuit să adaug valoarea 1 funcției din J9: =TRANSPOSE(FILTER(F10#;G10#=0)+1). Această transpozare a valorilor rezultat mă ajută să determin ceea ce se întâmplă în zona J10.
Funcția din J10 generează numărul de perechi pentru primul 0 din direcția Est. Apoi pe K10 aplic aceeași funcție.
Problema acestei metode de implementare este dată de faptul că dacă aș avea mai mulți de 0 în șirul original, atunci ar trebui să copii manual formula în dreapta. Pentru a expune perechile unice în ordinea lor folosesc în M10 o combinație de TOCOL() cu UNIQUE() și SORT() apoi număr aceste valori în Q10.
Treaba oarecum mai dificilă a fost să integrez toate aceste coloane și formule de comparație într-o singură funcție complet dinamică. Am ajuns cu greu la rezultat, din aproape în aproape.
Primele variabile sunt echivalentul din explicațiile anterioare. Prima provocare a fost să determin valorile echivalente din J9, valori care se regăsesc în variabila cols. Doar că nu pentru a putea calcula această variabilă aveam nevoie de o funcție Lambda() recursivă definită în variabila fRecursive. Această funcție o folosesc pentru a face filtrarea valorii echivalente pozițiilor 0 din șirul spre Est. fRecursive doar definește ce să facă funcția mai jos și care sunt parametrii. Ca să pot vedea rezultatele intermediare am creat un tabel în variabila tabi care adună coloană cu coloană variabilele definite anterior. IFNA() în folosesc în acest context pentru a elimina erorile NA determinate de faptul că numărul de elemente a lui cols poate fi mai mic decât numărul de elemente a șirului.
Rezultatul până la tabi este:
Marea provocare a apărut la procedura de calculare a perechilor pe datele din tabi. Ca să pot determina perechile de mașini după algoritmul explicat pentru celula J10, a trebuit să revin la funcția MAKEARRAY() pentru ca calcula o matrice dinamică cu numărul de linii exchivalent numărului de elemente ale șirului și numărul de coloane echivalent numărului de 0 întâlnit. Rezultatul intermediar din variabila tabperechi este:
Apoi în variabila peru am determinat perechile unice, în variabila nr am determinat numărul lor, după care am făcut o combinație de HSTACK cu VSTACK pentru a genera un tabel dinamic, cu tot cu capul de tabel.
Dincolo de aplicabilitatea în monitorizarea traficului auto, PassingCars poate fi adaptat în domeniul economic pentru:
Analiza cererii și ofertei pe piețele bursiere – Numărarea de câte ori o ofertă de cumpărare satisface o cerere de vânzare sau invers.
Gestionarea stocurilor – Monitorizarea cererilor de produse într-un depozit și numărarea momentelor în care sosirile de stocuri (oferte) satisfac cererile.
Fluxul de aprovizionare într-o fabrică – Cererile pentru piese specifice și momentele în care acestea sunt furnizate.
Problema CountDiv
Este o problemă clasică de algoritmică care se referă la calcularea numărului de divizori ai unui număr dat într-un interval specificat. De exemplu, dacă intervalul este [a, b] și numărul dat este n, problema solicită determinarea numărului de divizori ai lui n care se află în intervalul [a, b].
Exemplu: Considerați intervalul [1, 10] și numărul dat 20. Divizorii lui 20 în acest interval sunt 1, 2, 4, 5 și 10. Prin urmare, numărul de divizori ai lui 20 în intervalul [1, 10] este 5.
În analiza de date, se poate folosi pentru a număra evenimente periodice într-un interval de timp. De exemplu, dacă avem date despre evenimente care se întâmplă la fiecare 10 zile și vrem să știm câte astfel de evenimente au avut loc într-o anumită perioadă de timp.
Exemplu: Dacă avem evenimente la fiecare 10 zile și dorim să știm câte evenimente au avut loc între ziua 15 și ziua 95. A = 15, B = 95, K = 10
Pentru a afla numărul de evenimente care se întâmplă într-o lună (A 1 – start, B 31 final) odată la 4 zile (K 4) trebuie să caclulăm întregul împărțirii lui B la K apoi întregul împărțirii lui A-1 la K după care facem diferența între rezultate.
Dacă dorim să aflăm zilele din calendar pentru care trebuie să programăm acele acțiuni, am propus în G2 formula:
pentru generare a unei secvențe de numere pornind de la numărul de divizori (E4) în secvențe de câte K (B3). Apoi în pentur a determina numărul de la care se pornește trebuie să fac un calcul comparativ între A și K:
Daca K>=A atunci primul divizor devine K;
Daca K<A atunci :
daca restul impartirii lui A la K = 0 (MOD(A;K) atunci primul divizor este A;
daca nu sunt divizibile atunci formula de calcul al primului divizor din interval devine A + (K – MOD(A; K))
Condiția principală este ca A să fie mai mare ca B.
Ca să pot folosi într-o singură funcție personalizată, același algoritm poate fi implementat într-o funcție lambda care se poate salva în Name manager (Ctrl+F3). Funcția propusă ar fi:
în care B1, B2, B3 sunt celulele de testare pentru funcție. În această lambda putem identifica mai bine algoritmul de calcul explicat în pseudocod anterior.
În gestiunea stocurilor, algoritmul poate fi folosit pentru a determina câte reaprovizionări au avut loc într-un anumit interval de timp. De exemplu, dacă un produs trebuie reaprovizionat la fiecare 7 zile, putem calcula câte reaprovizionări au avut loc într-un interval de timp specificat. Alt exemplu din producție, dacă un echipament necesită mentenanță la fiecare 30 de zile și dorim să știm câte sesiuni de mentenanță au avut loc între ziua 50 și ziua 200.
Problema GenomicRangeQuery
Algoritmul GenomicRangeQuery este utilizat pentru a găsi factorul minim de impact al nucleotidelor într-o anumită secvență de ADN, în intervalele specificate. Avem o secvență de ADN reprezentată de un șir de caractere care conține literele A, C, G și T. Aceste litere au factorii de impact corespunzători: A = 1, C = 2, G = 3, T = 4. Trebuie să răspundem la mai multe interogări de tip interval, unde pentru fiecare interogare, ni se cere să găsim factorul minim de impact al nucleotidelor într-un sub-interval al secvenței de ADN. Un șir de caractere S reprezentând secvența de ADN. Două array-uri P și Q de aceeași lungime, unde fiecare pereche (P[i], Q[i]) definește un interval [P[i], Q[i]] în șirul S. Pentru fiecare interogare (P[i], Q[i]), se va returna minimul factorilor de impact al nucleotidelor din intervalul [P[i], Q[i]].
În contextul geneticii, termenul „factor de impact al nucleotidelor” nu este unul uzual. Însă, în multe probleme algoritmice, acest termen se referă la o reprezentare numerică simplificată pentru a evalua rapid o secvență genetică. Totuși, dacă ne referim la interpretarea nucleotidelor și la impactul lor în biologie, putem discuta despre semnificația biologică a diferitelor nucleotide (baze ADN: adenina (A), citozina (C), guanina (G), timina (T)) și cum anumite secvențe pot afecta funcționarea genelor.
Propunerea de rezolvare în Excel presupune descompunerea șirurilor de intrare, așezarea lor pe diferite celule și metode de extragere și funcții de căutare.
Intrările în model sunt ADN, S – secvența P și Q cele două perechi din secvență pe care le căutăm. A9, D3, H3, I3 sunt funcții de descompunere a textului pe linii. în J3 folosesc o metodă cu OFFSET(). Cei care au mai lucrat în trecut cu el, au permanent tendința de a se duce spre zona de vectori dinamici sprea această funcție. Doar că mie mi-a spus odată un expert în Excel că funcțiile de acest tip sunt funcții volatile și nu se recomandă a se utiliza. Și totuși, le folosesc de câte ori am nevoie și nu găsesc altă soluție mai rapidă. DROP() este un pic mai complex pentru că trebuie să extragi un segment din vector, pozițiile de deasupra și de dedesupt.
Rezolvarea în descompuneri în diferite zone și funcții de căutare este destul de simplă în Excel. Problema este când încerci să le unifici… pentru că sunt prea mulți vectori de parcurs în cadrul aceleeași operații. Vă prezint în continuare funcția din B15. Nu sunt extraordinar de mândru pentru că m-am chinuit prea mult… iar eu am în Excel un principiu: Dacă te muncești prea mult ca să faci un lucru, înseamnă că ceva nu faci bine.
Marea problemă a fost să pot face un tabel intermediar cu valorile de start în căutare și lungimea segmentului care va trebui extras. Cele două coloane din imaginea de mai jos, echivalentul variabilei vtab pe care o definesc în LET cu ajutorul funcției recursive care se numește fRecursive.
Uneori când sunt prea mulți vectori de parcurs, atunci segmentăm funcția în rezultate intermediare prin intermediul altor funcții LET() dar în care de multe ori definim astfel de funcții recursive. Funcțiile recursive pot fi definite și extern în Name manager (Ctrl+F3).
Cheia în funcția fRrecursive din definirea vtab este obținerea lungimii șirului de extragere (cea de-a doua coloană). Pentru a face această operațiune am folosit variabila vRows care prin BYROW() calculează diferența dintre coloanele P și Q (funcțiile TAKE) la care adaugă valoarea 1, pentru că în parcurgerea vectorilor din Excel cu funcții INDEX() de cele mai multe ori pornim de la valoarea 1.
Ulterior după ce a fost definit tabelul vtab folosim maximul din a doua coloană în variabila ac și numărul de linii rezultat în variabila ar. Aceste două variabile le folosim mai jos în variabila tabfin în care creem un tabel de ac coloane și ar linii pentru care aplicăm lambda care ne ajută la indexarea valorilor din segmentul ADN stocate în variabila vvADN.
valfin este ultima variabilă prin care BYROW() calculează minimul de pe fiecare linie.
Cel mai greu în rezolvare am ajuns la cele două valori coloane din vtab.
Analiza pieței de acțiuni
Dincolo de această problemă, algoritmul se poate aplica în domeniul economic pentru a ajuta la decizia de a investi sau nu într-un pachet de acțiuni. Se dă un șir de prețuri zilnice ale unei acțiuni și vrei să găsești prețul minim dintr-un anumit interval de zile pentru a lua decizii de investiții. Variabilele de intrare:
S (prețuri acțiuni): Un șir de prețuri zilnice ale acțiunilor.
P și Q (intervale de interogare): Două liste care conțin perechi de început și sfârșit pentru fiecare interval de zile în care vrei să analizezi prețul minim.
S = [23, 29, 21, 32, 25, 28, 24] (prețurile zilnice ale acțiunii) P = [1, 2, 4] (începutul intervalelor de interogare) Q = [3, 5, 6] (sfârșitul intervalelor de interogare)
Explicația lui P și Q. Intervalul 1: de la ziua 1 la ziua 3 Intervalul 2: de la ziua 2 la ziua 5 Intervalul 3: de la ziua 4 la ziua 6
Pentru a calcula prețurile minime trebuie să știm că nu mai avem din funcția anterioară variabilele specifice pentru vADN si vvADN. Noua funcție care este derivată din cea anterioară este:
Dincolo de dificultatea de implementare în Excel, GenomicRangeQuery este un algoritm foarte important de umrărit pentru că poate aplica (dincolo de minim) orice funcție asupra unor intervale de date definite ceea ce poate permite rezolvarea unor probleme de complexitate oarecum mai ridicată.
Problema MinAvgTwoSlice
Algoritmul MinAvgTwoSlice este o soluție la o problemă de găsire a unei subsecvențe continue de dimensiune minimă (de cel puțin două elemente) într-un șir de numere întregi, astfel încât media aritmetică a acestei subsecvențe să fie cât mai mică posibil. Problema este oarecum asemănătoare cu GenomicRangeQuery doar că de data aceasta trebuie să calculăm media aritmetică pe toate intervalele posibile, nu doar pe câteva intervale specificate.
Propunere de rezolvare
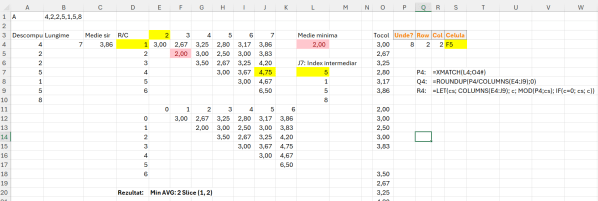
În rezolvarea problemei prin descompuneri, ca să pot face un tabel de căutare din două dimensiuni specifice lungimii șirului A, am introdus în E3 funcția: =SEQUENCE(;B4-1;2) în care în B4 avem lungimea șirului, -1 ca să pot avea același număr de elemente pornid de la 2. Aceste valori le folosesc pentru a specifica faptul că în algoritm nu pot porni de la 1:1 ci de la 1:2. La D4 am folosit funcția =SEQUENCE(B4-1) cu start de la 1 (nespecificat) dar ca să aibă același număr de elemente cu numărul de coloane. Folosesc -1 pentru că un șir intermediar nu poate porni de la ultima poziție a sa, cerința algoritmului fiind să ne raportăm la minim două elemente. In E4 am introdus apoi funcția de medie dinamică pe baza indexării liniilor cu coloanele. =IF($D4>=E$3;””;AVERAGE(INDEX($A$4#;$D4):INDEX($A$4#;E$3))). Rezultatul intermediar care ar apărea în J7 înainte de a face media este prezentat în imagine. Ca să pot afla apoi celula unde se află aceasă valoare minimă, am utilizat în S4 o funcție pe care o dezvoltasem mai demult pentru căutarea adresei unei celule dintr-un tabel pe baza unei valori specificate. Rezultatele intermediare pentru această funcție sunt specificate în P4, Q4 și R4.
Trebuie menționat că limită a acestei funcții că ea funcționează doar pentru tabele de date poziționate în sectorul de coloane A:Z.
Variabila aria conține tabelul de date pe care dorim să-l analizăm pentru a căuta valoarea pe care am obținut-o în celula L4. Acolo este trecută valoarea de căutare, stocată în variabila unde. Variabila unde scanează valoarea din L4 pe coloana obținută din aducerea la o dimensiune a tabelului aria. Ca să determin coloana din foaia de calcul în care se află valoarea folosesc un let care calculează poziția celulei în aria la care adună valoarea variabilei ca, care reprezintă numărul coloanei din foaia de calcul la care începe aria. Valoarea rezultat este stocată în variabila col. Aceeași procedură un pic simplificată este și la determinarea valorii variabilei row care este o rotunjire în sus (ROUNDUP) a locului unde se află valoarea în vectorul pe coloană împărțit la nnumărul de coloane al ariei, la care se adaugă valoarea variabilei ra care calculează linia la care începe aria în foaia de calcul. Ulterior calculez variabila cel prin care determin caracterul alfabetic de la A la Z. Litera A are codul 65 de aceea încep de la 64 în CHAR().
Pentru a întoarce rezultatul din E20 care include media minima și slice echivalent în poziții din șir folosesc următoarea funcție:
Reprezentarea variabilei tab este în imaginea de la soluția problemei în aria E12:K18. Celelalte variabile sunt rezultate intermediare explicate în problemă.
În economie acest algoritm ar putea fi utilizat în analiza costurilor de producție. De exemplu într-o fabrică se înregistrează costurile zilnice de producție. Un manager ar putea încerca să identifice media cea mai mică pe cel mai mic interval de zile, unde costurile au fost cele mai mic. În felul acesta poate corela cu alte date pentru a identifica ce s-a făcut diferit pentru a obține costuri mai scăzute.
Exemplu de problemă pentru un șir de date:
Cam asta a fost pentru acest articol. Multă treabă mai este…





![Problema PassingCars ]n Excel](https://valygreavu.com/wp-content/uploads/2024/05/image-11.png)










