În articolul trecut, expuneam problemele pe care le putem avea dacă păstrăm datele într-un tabel cu celule unite (merged). Articolul curent este mai mult un exercițiu de prezentare a unor funcții dinamice pentru rezolvarea problemei de însumare a valorilor dintr-un tabel cu merged cells. Atenție! Nivelul de dificultate poate fi considerat prea ridicat, dar încerc să explic pas cu pas.
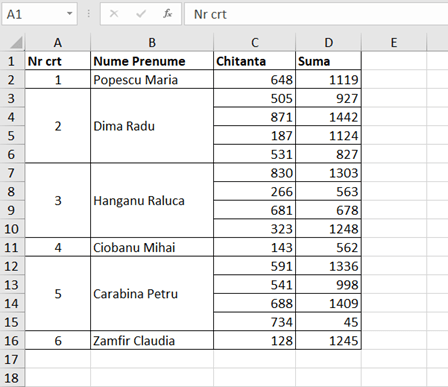
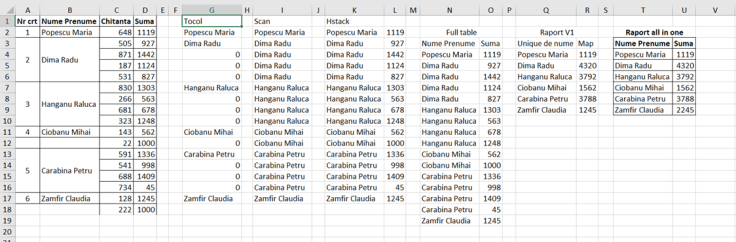
În imagine este prezentat tabelul original, coloanele A:D și raportul final în coloanele T:U.
Formula din T3 este:
=LET(tc; TOCOL(B2:B100);
coln; SCAN(0;tc;LAMBDA(a;v;IF(a=0;v;IF(v=0;a;v))));
ft; HSTACK(coln; D2:D100);
un; UNIQUE(TAKE(ft;;1));
suma; BYROW(un;LAMBDA(r; SUM(FILTER(TAKE(ft;;-1);TAKE(ft;;1)=r))));
HSTACK(un; suma))
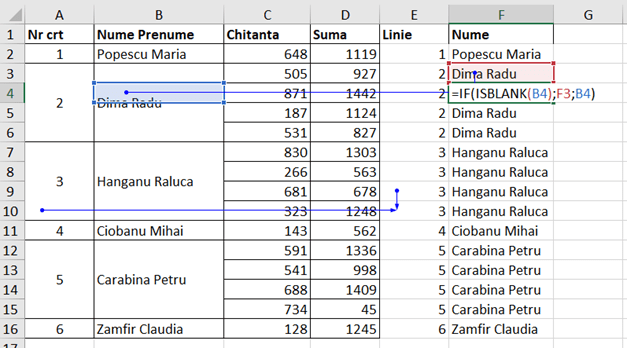
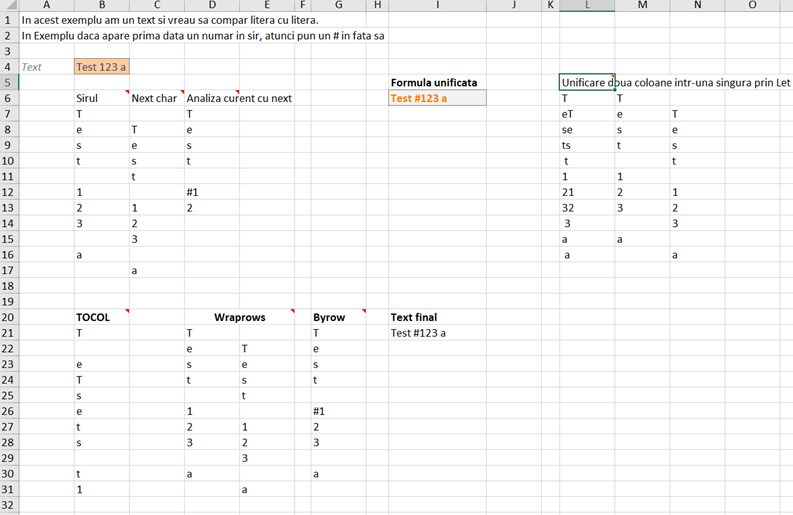
Ca să ajungem gradual la această formulă, în coloana G avem formula: =TOCOL(B2:B17)
Rezultatul formulei este un array care conține valorile specifice din tabelul cu date, înlocuind celulele din merged cells cu 0. Notam în articolul precedent că în merged cells, valoarea afișată se află doar în prima celulă din bloc, restul fiind vide. TOCOL() realizează automat umplerea cu 0 a celulelor blank.
Ca să pot completa automat valorile 0 cu numele celui din blocul de celule, propun în coloana I, funcția =SCAN(0;G2#;LAMBDA(a;v;IF(a=0;v;IF(v=0;a;v)))) , în care:
0 este valoarea curentă de la care pornește scanarea. În fapt ea este imput pentru parametrul a (acumulator) din LAMBDA(). G2# este referința către rezultatul funcției TOCOL() din etapa precedentă. Esența în rezolvare este funcția LAMBDA() care trebuie să aibă în SCAN() doi parametri: a – acumulat, v – valoare curentă. Normal, acești parametri se pot chema și altfel, dar am văzut că mulți utilizatori de Excel preferă acest format. SCAN-ul evaluează fiecare valoare din sursa de date (G2#) și pe baza execuției din LAMBDA afișează o valoare la fiecare linie. În momentul în care începe execuția LAMBDA() parametrul a are valoarea 0. Dacă ea este 0 atunci se afișează valoarea curentă din blocul de date. De asemenea, a preia automat valoarea curentă a lui V care este valoarea de linie. La următoarea linie, dacă v nu era 0, a devine primul nume, deci la rândul următor a nu va mai fi 0 IF-ul intr-înd pe FALSE. Aici, dacă V-ul este 0 se preia valoarea acumulator ceea ce înseamnă valoarea de deasupra. Dacă V nu este 0 atunci se preia noul V. Pare complicat, dar în fapt sunt doar două IF-uri, care trebuie să returneze două valori. Mai greu este să ajungi la înțelegerea care este valoarea lui V și a lui A pe o anumită linie.
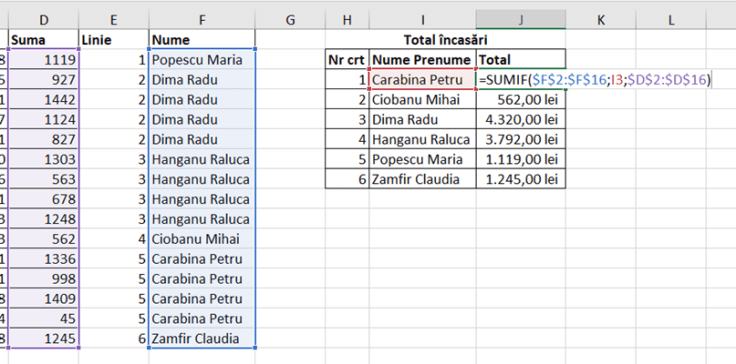
Pentru a obține acum un tabel cu coloana rezultată din SCAN și coloana de valori din tabelul inițial, în K2 am folosit funcția: =HSTACK(I2#;D2:D17)
HSTACK() este o funcție care pentru fiecare parametru generează o nouă coloană într-un tabel array rezultat. Dacă aș fi folosit VSTACK() atunci rezultatul ar fi fost o singură coloană cu primele linii din prima coloană continuate cu cea din a doua coloană.
Combinând aceste 3 funcții avem o primă funcție LET() cu variabilele TC, COLN și FT. FT este de fapt final table pe care trebuie să-l parcurg pentru a ajunge la nume unice cu sume cumulate.
Ca să pot obține formula finală, în Q4: am introdus o simplă funcție UNIQUE() pe baza datelor din N:O. Formula este aplicată doar pentru coloana de nume. Pentru a calcula acum valorile ar fi foarte simplu să utilizăm un SUMIF() dar intenția mea este de a folosi acest calcul direct într-un LET() care presupune că trebuie să tratăm dinamic coloana de nume, linie cu linie, necunoscând totalul de linii rezultat.
Rezolvarea în această etapă se poate realiza cu MAP() sau BYROW() depinde de modul de abordare: BYROW() ia toate coloanele din linie, MAP() apelează doar o singură coloană dintr-un tabel, linie cu linie.
Am preferat BYROW() pentru această formulă pentru a prezenta o altă funcție, MAP() fiind destul de des prezentat în articolele de pe internet.
Astfel funcția din R4: =BYROW(Q4#;LAMBDA(r; SUM(FILTER($O$4:$O$19;$N$4:$N$19=r)))) , în care:
Q4# este coloana cu nume unice, r este parametrul din LAMBDA() care face referire la linia curentă, după care avem o sumă pe un FILTER() pe coloana de sume, pe baza condiției ca numele să fie egal cu valoarea lui r.
Dacă preferați MAP() în formula din R4 schimbăm pur și simplu BYROW cu MAP și funcționează identic.
Această a doua parte se transformă în formula din T3, în variabilele un și suma. Având în vedere că sunt înglobate într-un LET() nu avem cum să ne adresăm în ele la anumite celule, blocuri de celule dintr-o foaie de calcul. Această problemă o rezolvăm prin funcția TAKE() care ne permite să preluăm dintr-un tabel definit anterior, în cazul de față ft, un anumit număr de linii sau coloane. Al doilea parametru din TAKE() este numărul de linii , care la mine este omis, iar al treilea parametru este numărul de coloane. Dacă specificăm valoarea 1 va prelua prima coloana din stânga, valoarea 2, primele două coloane din stânga, iar dacă trecem valori cu -1, -2 se vor prelua ultima coloană din dreapta dintr-un tabel definit sau ultimele două (-2).
Ultima operație din formula din T3 este dată de unificarea prin HSTACK() a variabilelor un (nume unice) și suma (valorile însumate).
Puteți să descărcați fișierul Excel din acest articol de aici. Vă reamintesc că funcțiile dinamice sunt disponibile doar în anumite versiuni de Excel.
În concluzia acestui articol: nu mai utilizați tabele merged… și nu mai colectați date în Excel. Folosiți SharePoint!
P.S. Sunt convins că această problemă se poate rezolva și cu Power Query… dar poate într-un articol viitor.