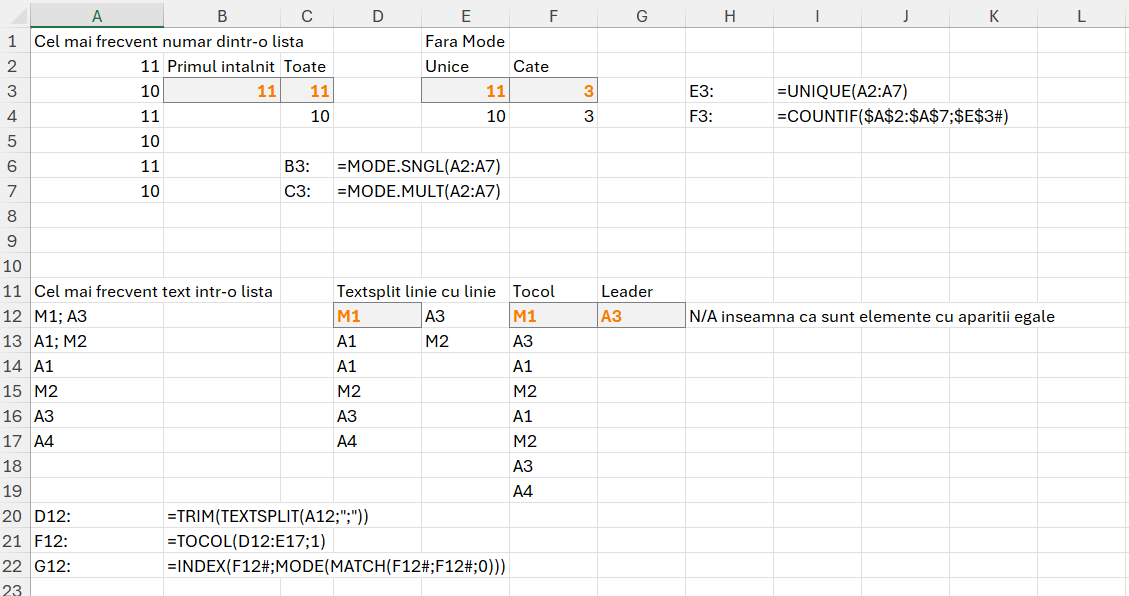
Dacă nu v-a plăcut niciodată matematica, mai bine nu citiți acest articol. Vă fac eu un rezumat: E nasol! :)
Dar e foarte fain și provocator pentru matematicieni și cei cărora le place să lucreze cu numere. În același timp, dincolo de programare propun o metodă de rezolvare nouă a problemelor de determinare a numerelor prime, desigur cu limitările aferente Excelului care poate face operații cu numere de până la 15 cifre sau în care numărul de linii este limitat la 1048576 adică 2 la puterea 20.
Prezentul articol propune o metodă de rezolvare a problemelor de pe site-ul Codility și le găsiți în detaliu la adresa: https://app.codility.com/programmers/lessons/10-prime_and_composite_numbers/
Fiind vorba de mai multă matematică să începem cu…
Puțină teorie
Un număr natural 𝑛 > 1 este numit prim dacă are exact două divizori pozitivi: 1 și n. Exemple: 2, 3, 5, 7, 11 etc. Un număr natural 𝑛 > 1 care nu este prim este numit compus. Acesta are mai mult de doi divizori. Exemple: 4, 6, 8, 9, 12 etc.
Fără a intra în prea multe detalii matematice, verificarea dacă un număr este prim are la bază testul lui Fermat care a fost extins de către matematicianul James Grime la metoda AKS, care are o probabilitate mai mare de soluții corecte. În matematica aplicată în criptografie, cea mai cunoscută metodă de determinare a unui număr prim este cunoscută sub denumirea de Miller-Rabin. Metoda este foarte complexă și presupune tehnica de ridicare la puterea numărului analizat, ceea ce în Excel este limitativ. Aplicand testul N maxim poate fi 46 care nu este numar prim. La urmatorul numar, 47, 2^46 rezulta un numar complex de 15 cifre cu care Excelul nu mai poate lucra. Nici formula Willans nu ne ajuta pentru ca avem o componenta de factorial care ne duce la numere mari la aceeasi limitare.
În metoda de rezolvare propusă de mine, am utilizat tehnica de a genera o secvență de numere de la 1 la N după care pe secvență am determinat dacă numărul N împărțit la valoarea curentă este un număr întreg sau zecimal. Voi detalia în secțiunea următoare. Doar că această tehnică a generării de secvențe de numere este costisitoare ca timp de execuție și limitată la N de pana la 2^20, echivalentul numărului de linii din Excel. În căutarea unei metode de optimizare am ajuns la algoritmul Prim-Dijkstra care presupune, în mod simplificat, calcularea radicalului din N, după care verificarea factorilor ramasi de la 2 până la valoare radical. Tehnica aceasta îmi permite să analizez dacă un număr este prim sau nu până la valoarea 1.099.511.627.776 echivalentului lui 2 la puterea 40, un număr de 13 cifre cu care poate lucra Excel. Limitarea este data de faptul că nu pot genera secvențe mai mari de 2^20 care este radicalul lui 2^40.
Exemplificare implementare algoritm Prim-Dijkstra
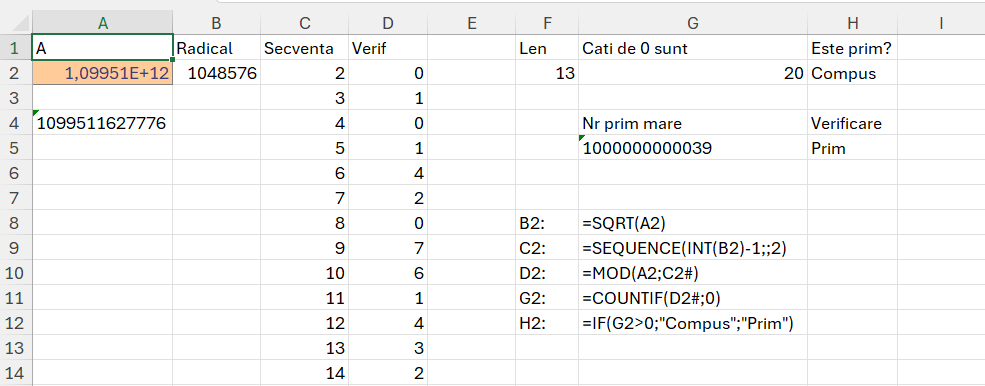
În cazul numerelor prime 2 și 3 modelul prezentat returnează eroare din cauză că nu se poate genera secvența pentru că radicalul este mai mic decât 2. În cazul acesta pentru a rezolva problema lui 2 și 3 funcțiile din C2 și D2 trebuie tratate cu un IFERROR().
Funcția unificată este destul de simplă și are la bază funcțiile prezentate în imagine:
=LET(a;--G5;
radical;SQRT(a);
sec;SEQUENCE(INT(radical)-1;;2);
unmod;IFERROR(a/sec-INT(a/sec);1);
TAKE(IF(FILTER(unmod;unmod=0;"x")="x";
"Prim";
"Compus");1;1))în care variabila unmod este cea care-mi determină în mod diferite față de funcția MOD() prezentată anterior, valoarea 0 sau un număr zecimal, în funcție dacă numărul N se împarte la numărul curent de le secvența din variabila sec.
În încheierea acestei secțiuni, Excelul dispune de un set destul de mare de funcții matematice pe care le putem utiliza în diferite contexte. Pentru mine una din cele mai utile este funcția MOD() explicată și în articolul Modele de algoritmi in #Excel – Vectori (2.1). Apoi mai folosesc MROUND() pentru a rotunji zecimalele la un set de intervale predefinite, un înlocuitor mai nou al funcției CEILING(). De asemenea, folosesc destul de des funcțiile de randomizare și cele de rotunjire. SEQUENCE() care este tot o funcție matematică o utilizez foarte des în locul FOR-ului din programarea clasică și mai folosesc adeseore ISODD sau ISEVEN pentru a determina dacă am un număr par sau impar într-o zona a unei funcții. Interesantă de studiat și prezentat, când o fi timp, funcția AGGREGATE.
În continuarea articolului propun câteva metode de rezolvare a problemelor cu numere prime în Excel.
Problema CountFactors
Dat fiind un număr întreg pozitiv N, problema cere să identificăm numărul total de divizori ai acestui număr, adică numărul de factori pozitivi care împart N exact fără a lăsa rest. Pe scurt k este un divizor al lui N dacă restul împărțirii lui N la k este zero.
În cazul acestei probleme nu putem aplica algoritmul Prim-Dijkstra pentru că ne trebuie toți divizorii. De exemplu dacă ne referim la numărul 24, radical din 24 = 4,89 ceea ce înseamnă că nu luăm în calcul valoarea 6, 8, 12 care sunt divizori ai lui 24. Pentru optimizare am putea sa inmultim fiecare din divizorii sub radical intre ei pentru a determina in oglinda divizorii urmatori.
Rezolvarea problemei pas cu pas:

În cazul numerelor prime vom obține doar două valori: 1 și N. Funcția unificată din G6 este:
=LET(_n;A2;
factors;SEQUENCE(_n);
mods; MAP(factors;LAMBDA(v;_n/v));
rezfactors; IF(mods-INT(mods)=0;mods;"");
"Nr factori: "& COUNT(rezfactors)&" - "&TEXTJOIN(";";TRUE;SORT(rezfactors)))În care în variabila mods am împărțit numărul _n la valoarea corentă de pe secvența factors. În partea de rezultat am realizat o concatenare ca să includ și factorii.
Funcția lucrează destul de repede pentru numere până la 2^20-1 acest număr (1.048.575) având 48 de factori.
Aplicații practice
- Criptografie: Factorizarea numerelor mari este esențială pentru algoritmii de criptare.
- Teoria numerelor: Analiza proprietăților numerelor în baza divizibilității.
- Probleme de optimizare: Factorii unui număr pot fi utilizați pentru a găsi soluții optime în anumite probleme de împărțire sau combinatorică.
Problema MinPerimeterRectangle
Problema MinPerimeterRectangle se încadrează în categoria problemelor legate de factorizarea numerelor și geometrie elementară.
Cerința este să identificăm dreptunghiul cu cel mai mic perimetru care poate fi format folosind divizorii unui număr întreg pozitiv N. Un dreptunghi este format din laturile a și b care satisfac relația: a×b=N. Perimetrul acestui dreptunghi este dat de formula: P=2×(a+b). În mod evident, pentru a minimiza perimetrul, diferența dintre a și b ar trebui să fie cât mai mică posibil, adică a și b ar trebui să fie cât mai apropiate între ele.
Pentru a găsi perechea (a,b) optimă, putem parcurge toți divizorii a ai lui N, apoi calculăm b=N/a. Calculăm perimetrul pentru fiecare astfel de pereche și reținem perimetrul minim.
Propunerea de rezolvare este un pic mai complicată în Excel.
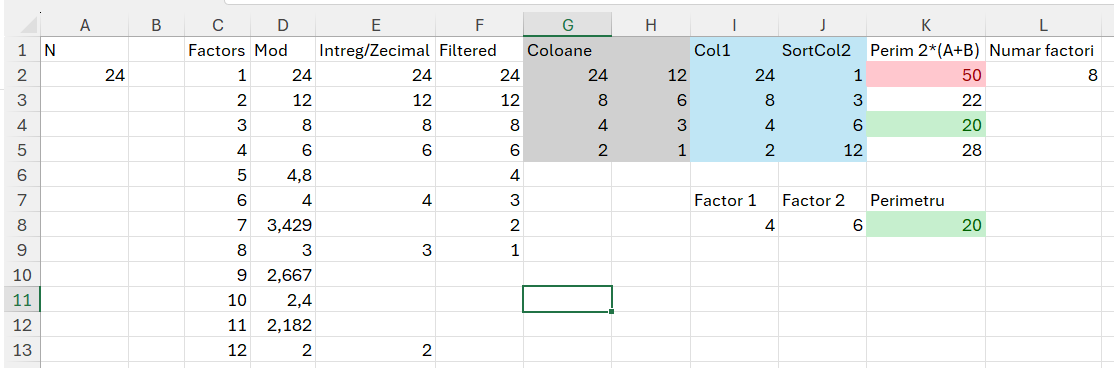
Până la E2 este problema cunoscută prezentată anterior. Ca să pot înmulți numerele între ele, trevuie să le transpun pe două coloane. Doar că în cazul în care numărul de factori ai lui N este un număr impar vom obține în zona G:H o eroare și tot algoritmul nu mai funcționează corect. De aceea, prezint formula direct mai complicată pentru a genera tabelul Coloane (G2:H5):
=LET(filtered;F2#;
rr;ROWS(filtered);
IF(ISEVEN(rr);WRAPROWS(filtered;2);
HSTACK(TAKE(filtered;INT(rr/2)+1);TAKE(filtered;-INT(rr/2)-1))
))în care verific dacă numărul de linii este un număr par și dacă da împart filtrarea fin F2# la două coloane. WRAPROWS împarte un vector în linii a câte n coloane specificate ca parametrul 2 din exemplul nostru. Numărul de linii variază în funcție de dimensiunea vectorului.
Ca să putem în continuare să facem înmulțirea trebuie să sortăm a doua coloană ascendent. Pentru asta în I2 am folosit funcția: =TAKE(G2#;;1) pentru a prelua prima coloana din tabelul Coloane, as-is iar in J2 am folosit funcția: =SORT(TAKE(G2#;;-1)) pentru a sorta ascendent a doua coloană din tabelul din G2#. Calcularea perimetrului este apoi destul de simplă: =2*(I2#+J2#) iar prin formatare condiționată am formatat cu verde cea mai mică valoare, corespondetă laturilor factori 4, 6. Este demonstrată în acest fel ipoteza din introducere în care cei mai apropiați factori determină cel mai mic perimetru.
Funcția integrată pentru a determina direct factorii si perimetrul cel mai mic, este:
=LET(_n;A2;
factors;SEQUENCE(_n);
mods;MAP(factors;LAMBDA(v;_n/v));
rezfactors;IF(mods-INT(mods)=0;mods;"");
filtered;FILTER(rezfactors;ISNUMBER(rezfactors));
rr; ROWS(filtered);
coloane; IF(ISEVEN(rr); WRAPROWS(filtered;2);
HSTACK(TAKE(filtered;INT(rr/2)+1);TAKE(filtered;-INT(rr/2)-1)));
_col1; TAKE(coloane;;1);
_col2; SORT(TAKE(coloane;;-1));
tabf; HSTACK(_col1;_col2; 2*(_col1+_col2));
perimmin; FILTER(tabf; TAKE(tabf;;-1)=MIN(TAKE(tabf;;-1)));
perimmin
)în care identificăm explicațiile anterioare dar sub formă de variabile iar la final avem un FILTER() pe minimum de perimetru.
Aplicații practice
- Optimizarea costurilor: În construcții, reducerea perimetrului poate însemna reducerea costurilor de material pentru garduri sau borduri, având o anumită arie dată.
- Design de produse: În industrie, minimizarea perimetrului unui dreptunghi poate fi importantă pentru ambalaje sau alte produse, unde materialul folosit pentru margini trebuie să fie minimizat.
- Logistică: În depozitare și ambalare, calcularea cutiei sau ambalajului cu perimetrul minim pentru o anumită suprafață (de exemplu, etichete) poate reduce consumul de material și costuri.
Problema Flags
Problema Flags este o problemă clasică de optimizare, care presupune plasarea unui număr maxim de steaguri pe vârfurile unei secvențe montane, respectând anumite condiții.
Dată fiind o listă de înălțimi reprezentate printr-un vector A, fiecare element din vector reprezintă înălțimea unui vârf sau a unei depresiuni dintr-un peisaj montan. Un vârf este definit ca o poziție i pentru care: A[i−1]A[i+1]. Distanța dintre două steaguri consecutive să fie de cel puțin K unități, unde K este numărul total de steaguri.
Propunere de rezolvare.
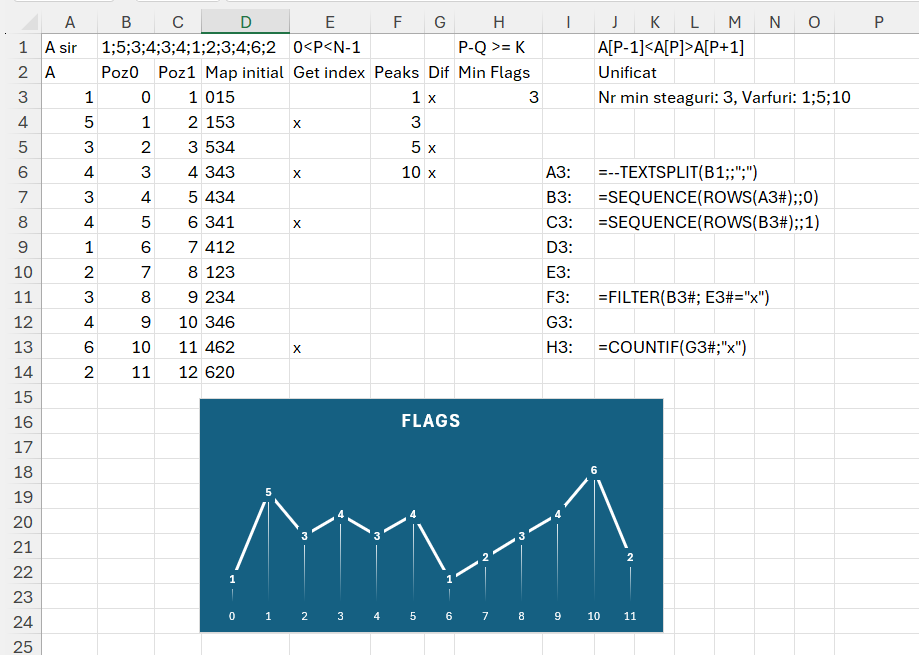
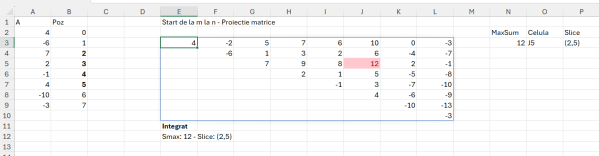
În B2 avem șirul de numere care reprezintă vârful. Șirul este transformat în vector în A3. Inspirat de cei de la Codility am realizat și eu graficul din valoarea vârfurilor. Din câte observăm avem vârfuri în poziția (pornind de la 0) 1, 3, 5, 10. Doar că problema Flags are această chichiță că steagurile trebuie să fie la dimensiune de cel puțin numărul lor între ele. Am identificat că sunt 4 steaguri inițial. Diferența între poziția steagului 1 și 3 nu este de 4, ceea ce înseamnă că steagul 3 cade. Asta este cerința… eu aș fi făcut că dacă sunt două vârfuri consecutive egale punem un singur steag.
În D3 doar am vrut să testez indexarea. Mă gândeam la început să folosesc metoda matricei de triplete, dar nu are sens pentru că nu comparăm toate vârfurile între ele cu doar poziția curentă cu cea anterioară și următoare. În E3 marchez de fapt cu valoarea x valorile care îndeplinesc condiția de vârf. Funcția completă pentru marcare este:
=MAP(C3#; LAMBDA(v; LET(a; A3#;
_p_1; IF(v=1; 0; INDEX(a; v-1));
_p; INDEX(a;v);
_p_2; IFERROR(INDEX(a; v+1);0);
IF(AND(_p_1<_p;_p >_p_2); "x"; ""))))în care prin funcția MAP parcurg vectorul C3# iar pentru fiecare valoarea v din acesta calculez valoarea variabilelor _p_1, _p și _p_2 pentru a extrage de pe vectorul A3# valoarile și a le compara în IF-ul de la final. Dacă ele îndeplinesc condiția cerută de problemă, atunci marcăm cu x.
În F3 filtrez valorile poziției pe format vector (start de la 0). O mică bătaie de cap o avem în G3 pentru a determina optimul de steaguri prin diferență între poziția lor și numărul lor. Funcția din G3 este:
=LET(peaks;F3#;
seq;SEQUENCE(ROWS(peaks));
MAP(seq; LAMBDA(v;IF(v=1;"x";
IF(ABS(INDEX(peaks;v)-INDEX(peaks;v-1))>=ROWS(peaks);"x";
IF(v-2<1;"";
IF(ABS(INDEX(peaks;v)-INDEX(peaks;v-2))>=ROWS(peaks);"x";"")))))))în care scanez cu MAP() secvența rezultată din numărul de vârfuri inițial, în cazul nostru 4, după care pentru fiecare valoare calculez diferența absolută între termeni iar dacă aceasta este mai mare decât numărul de vârfuri inițial, marchez cu x. După cum observăm din rezultat rămân marcate vârfurile 1, 5 și 10, ceea ce determină un număr optim de 3 steaguri pe care le putem amplasa pe traseul montan.
Toată povestea aceasta unificată este prezentată în funcția următoare:
=LET( a; TEXTSPLIT(B1;;";");
_poz0; SEQUENCE(ROWS(a);;0);
_poz1; SEQUENCE(ROWS(a);;1);
gindex; MAP(_poz1; LAMBDA(v; LET(_p_1; IF(v=1;0;INDEX(a;v-1));
_p; INDEX(a;v);
_p_2; IFERROR(INDEX(a;v+1);0);
IF(AND(_p_1<_p;_p>_p_2);"x";""))));
rezfin; FILTER(_poz0;gindex="x");
minflags; LET(peaks;rezfin;
seq;SEQUENCE(ROWS(peaks));
MAP(seq; LAMBDA(v;IF(v=1;"x";
IF(ABS(INDEX(peaks;v)-INDEX(peaks;v-1))>=ROWS(peaks);"x";
IF(v-2<1;"";IF(ABS(INDEX(peaks;v)-INDEX(peaks;v-2))>=ROWS(peaks);"x";"")
))))));
ver; IFNA(HSTACK(a;_poz0;_poz1;gindex;rezfin;minflags);"");
pozminflag; FILTER(rezfin;minflags="x");
fin; "Nr min steaguri: "&COUNT(pozminflag)&", Varfuri: "&TEXTJOIN(";";TRUE;pozminflag);
fin)în care putem identifica valorile obținute în coloanele prezentate în imagine, totul cu un singur input: B1, șirul de valori. Având în vedere numărul de pași pe care trebuie să-i parcurgem până la rezultatul final, o tehnică pe care o utilizez este aceea de verificare pe parcurs. Asta o fac cu un HSTACK (variabila ver) în care acumulez rând pe rând coloanele pe care le obțin anterior. IFNA în folosesc pentru cazul în care numărul de linii de la o coloana la alta este diferit.
Aplicații practice
- Managementul resurselor: În industria minieră sau forestieră, optimizarea plasării resurselor (cum ar fi sonde sau senzori) poate urma o abordare similară, unde distanța minimă între resurse trebuie respectată.
- Planificarea rețelelor: În telecomunicații, plasarea antenelor sau a altor echipamente trebuie să respecte anumite distanțe minime pentru a evita interferențele.
- Logistica: În planificarea transporturilor sau a depozitelor, problema poate fi utilizată pentru a optimiza plasarea punctelor de control sau a stațiilor de verificare.
Problema Peaks
Aparent o variantă a problemei Flags, doar că nu mai avem limitarea k de distanță în amplasarea unor steaguri. Avem însă o cerință nouă care solicită împărțirea vectorului care reprezintă un sector montan în segmente egale ca dimensiune. Mai mult de atât fiecare segment trebuie să aibă un vârf. Cerința este foarte faină și are din nou legătură cu optimizarea din practică spre zone din economie în special finanțe și producție. Dozarea efortului ar fi în sinteză.
Propunere de rezolvare:
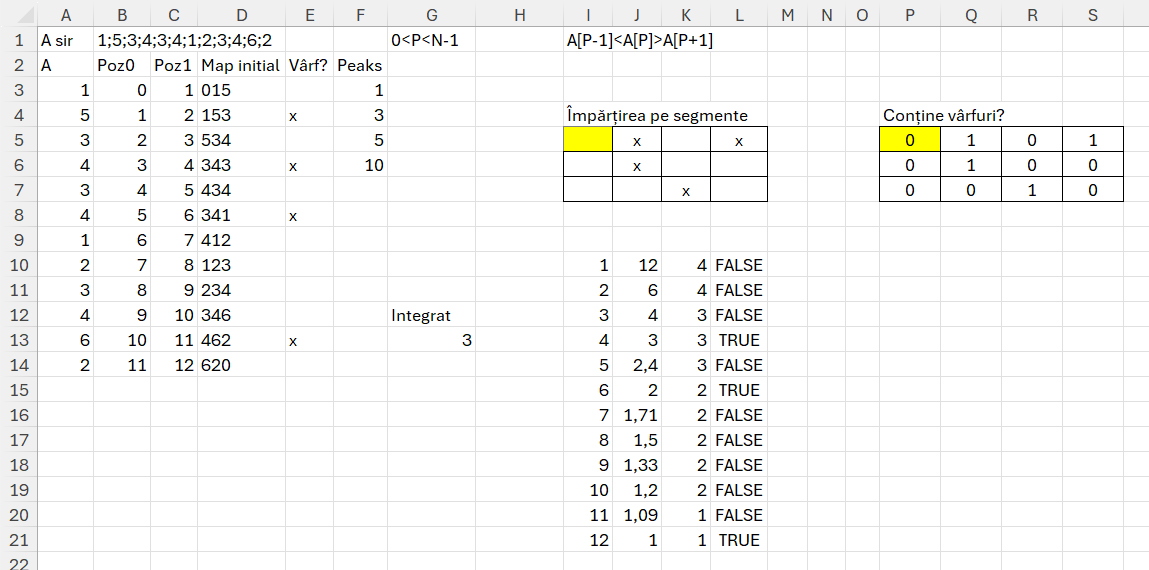
După cum se poate observa prima parte a problemei este asemnătoare cu Flags pentru că se obțin valorile vârfurilor. Apoi în I5 am folosit un WRAPROWS de vectorul cu vârfuri și am introdus manual valoarea coloanelor pe fiecare linie (2,3,4,5) pentru a obține cel puțin un x pe fiecare linie. În P5 am introdus funcția =IFERROR(FIND(„x”;I5#);0) pentru a calcula 1 sau 0 în funcție dacă conține x sau nu. Calculând suma pe linie putem vedea dacă numărul de segmente este optim. Numărăm apoi numărul de linii rezultat în funcție de dimensiunea vecotorului inițial și stabilim numărul de segmente în care se împarte optim vectorul, în cazul nostru 3. În zona I10 am unificat I5 și P5 pentru a putea calcula pe baza vectorului de vârfuri care este impărțirea optimă în segmente. observăm din tabel pe ultima coloană că putem avea mai multe valori adevărate pentru poziția 4, 6, 12, dar pe noi ne interesează numărul cel mai mic pentru că aceste valori reprezintă de fapt dimensiunea sub-segmentului iar coloana 3 numărul de linii rezultat care înseamnă total segmente. Conform cerinței problemei avem nevoie de cât mai multe segmente, dar pentru că pe coloana 2 nu obținem un număr egal (numărul de x pe fiecare linie) nu avem egalitate între coloana 2 și 3 pentru valoarile cu 4 segmente.
Bazându-mă pe experiența de lucru, am integrat toate funcțiile de pe parcurs în G13, funcția finală care determină optimul de subsegmente rezultat este:
=LET(gi; LET( a; TEXTSPLIT(B1;;";");
_poz0; SEQUENCE(ROWS(a);;0);
_poz1; SEQUENCE(ROWS(a);;1);
gindex; MAP(_poz1;
LAMBDA(v; LET(_p_1;IF(v=1;0;INDEX(a;v-1));
_p;INDEX(a;v);
_p_2;IFERROR(INDEX(a;v+1);0);
IF(AND(_p_1<_p;_p>_p_2);"x";""))));
gindex);
rrgi; ROWS(gi);
freq; LAMBDA(v; LET(ver; WRAPROWS(gi;v);
findver; IFERROR(FIND("x";ver);0);
rfv; ROWS(findver);
tabrez; BYROW(findver;LAMBDA(r;SUM(r)));
rowstr;ROWS(FILTER(tabrez;tabrez>0;0));
rowstr));
runfreq; MAKEARRAY(rrgi;1;LAMBDA(r;c;freq(r)));
tabi;HSTACK(SEQUENCE(rrgi);rrgi/SEQUENCE(rrgi);runfreq;rrgi/SEQUENCE(rrgi)=runfreq);
rezfin; MAX(CHOOSECOLS(FILTER(tabi;(TAKE(tabi;;-1)));3));
rezfin
)în care cheia este funcția recursivă freq care generează pentru fiecare valoare a lui r din runfreq un tabel de valori cu numărul de de x-uri pe care le avem pe fiecare segment.
gi este echivalentul vecotorului cu vârfuri din E3#.
rrgi este numărul de linii pe care le are vectorul de start, echivalent numerelor din șirul B1.
runfreq este echivalentul coloanei 3 din tabelul de testare prezentat anterior. El ne spune câte linii ar conține vârfuri (valoarea X) dacă am imparti vectorul în segmente de numărul celor specificate pe coloana 1 din tabelul din imagine.
tabi unifică prin HSTACK valorile asemnănător tabelului de testare și apoi inm rezfin facem filtrarea tabelului pe valoarea maximă de pe runfreq care îndeplineste criteriul de true.
Aplicații practice
- Analiza pieței: Poate fi folosită pentru a analiza ciclurile economice, divizând datele financiare în perioade de creștere și declin, asigurându-se că fiecare perioadă conține un punct maxim.
- Planificarea operațiunilor: În producție, poate ajuta la divizarea unui proces în etape, fiecare etapă având un punct de control sau un obiectiv intermediar atins.
- Gestionarea resurselor: În logistica, problema poate ajuta la optimizarea rutelor, asigurându-se că fiecare segment al rutei include o oprire sau un punct important.
Cam atât pentru acest articol. Excelul poate destul de mult… important în schimb este să exersăm pentru a putea rezolva probleme cât mai complete în mod cât mai automatizat.
Sper să fie util cuiva!