„Organizational change requires individual change.”
Context
În ultima perioadă circulă din ce în ce mai mult în media din România și nu numai, tema inteligenței artificiale. Pare un subiect de interes, mai ales că suportă multe combinații cu teoriile conspirației, fără a fi o conspirație în sine. Dar oare cât de pregătită este administrația publică din România, în fața (poate) unui următor val al digitalizării? Cât de pregătiți suntem acum cu tehnologiile pe care le avem să facem față unei comunicații cât mai apropiate de cetățean și ce servicii îi oferim? Folosim Social media pentru a comunica cu ei? Comunicarea on-line influențează oare deciziile pe care le ia administrația locală în folosul comunității?
Acestea sunt doar câteva din zecile de întrebări la care se încearcă să se răspundă în diferite cercuri de discuții mai mult sau mai puțin academice, sociale sau politice. În acest sens, o echipă de profesori din cadrul Universității „Alexandru Ioan Cuza” din Iași derulează o cercetare privind digitalizarea instituțiilor publice din România, pentru a propune soluții care să vină atât în sprijinul unei bune administrări, cât și a unor condiții mai performante în raport cu funcționarii din instituțiile publice. Urmărim să obținem o imagine detaliată a nivelului de digitalizare, a serviciilor publice online, a comunicării cu cetățenii și a provocărilor profesionale pentru funcționarii din cadrul sectorului public.
Cercetările academice pot fi relevante și pot conduce la soluții aplicabile și utile doar într-un proces participativ, prin cunoașterea în detaliu a percepțiilor, a opiniilor și a așteptărilor celor care, în diferite poziții executive sau de conducere în administrația publică, se confruntă cu limitări sau oportunități asociate digitalizării și comunicării online. Prin digitalizare în sensul acestui studiu, ne referim la calculatoare/laptopuri, aplicații și platforme de comunicare/altele similare.
Cercetări existente
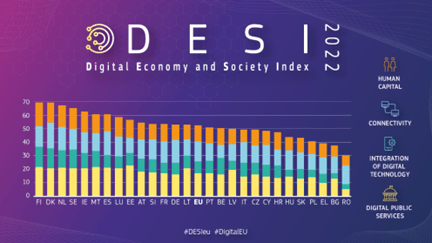
Cercetarea noastră a pornit de la indicatorul DESI (https://digital-strategy.ec.europa.eu/ro/policies/desi) în care România, ocupa în anul 2022 ultima poziție.
Nu avem detalii despre modul în care sunt colectate datele care compun acest indicator, dar în cercetarea noastră ne propunem să schimbăm modul de abordare, și să depășim bariera cantitativă a majorității cercetărilor, prin utilizarea metodologiei de cercetare calitativă ADKAR (https://www.prosci.com/methodology/adkar). Idea de bază este de identifica modul în care se comunică în prezent cu cetățenii și să înțelegem implicarea umană în procesul de integrare a tehnologiilor digitale în cadrul administrației publice locale. Aparent fiecare din noi dorește o schimbare în bine între instituțiile statului și cetățeni prin îmbunătățirea comunicării și a transparenței procesului decizional. Dar de cele mai multe ori suntem limitați de resursele materiale și financiare disponibile. În opinia noastră atât timp cât resursa umana este informată și deschisă la nou, abordarea temei digitalizării se poate transforma mult mai ușor într-o poveste de succes.
Proiectarea cercetării
Pentru a avea o imagine extinsă a percepției angajaților din instituțiile publice am introdus mai multe întrebări de tip open text, a căror răspuns va fi analizat în detaliu cu instrumente specifice de text.
Publicul țintă al chestionarului sunt Primăriile din întreaga țară, Prefecturile și Consiliile județene. Pentru a le adresa direct și specific, chestionarul a fost împărțit pe județe, un prim nivel al gradului de implicare și interes în sprijinul cercetării fiind chiar numărul de răspunsuri oferite în fiecare județ. Înțelegerea noastră este ca fiecare UAT să ne ofere cel puțin un răspuns complet la chestionar.
Una din provocările majore a fost colectarea datelor de contact a Primăriilor din țară. Ne-am fi așteptat ca undeva pe site-urile Guvernului sau Prefecturilor să găsim colecții de date de contact actualizate. Colectarea datelor de intrare a început cu site-ul https://data.gov.ro/ de pe care am descărcat un set de date cu primării. Din păcate în primă etapă am identificat doar numele UAT-urilor și mai multe detalii dar doar 482 de adrese de email și 531 de site-uri web din totalul de 3278 la nivel național.
|
Records |
Website |
|
|
3278 |
531 |
482 |
|
16,20% |
14,70% |
După mai multe încercări de colectare, folosind cu succes tehnici de web scraping și corecturi manuale în anumite cazuri, am reușit să colectăm 3186 adrese de primării, 42 prefecturi și tot atâtea adrese pentru consiliile județene.
Și metoda automată și cea manuală nu ne-a pus în situația de a identifica faptul că în multe cazuri site-urile oficiale ale primăriilor nu funcționează pentru preluare date de contact, iar în alte cazuri pe site-urile primăriilor există anumite adrese de email iar pe site-urile consiliilor județene există adrese vechi.
Din analiza adreselor de email am identificat că majoritatea primăriilor din țară folosesc ca adresă de contact o adresă de Yahoo Mail.
Top 15 Domenii după numărul de primării:
Rank
|
Domenii
|
Count
|
1
|
yahoo.com
|
1917
|
2
|
gmail.com
|
153
|
3
|
cjdolj.ro
|
110
|
4
|
cjmures.ro
|
102
|
5
|
cjbihor.ro
|
72
|
6
|
sejmh.ro
|
51
|
7
|
prefecturaprahova.ro
|
43
|
8
|
clicknet.ro
|
30
|
9
|
judetulolt.ro
|
22
|
10
|
artelecom.net
|
18
|
11
|
cjtimis.ro
|
17
|
12
|
yahoo.co.uk
|
13
|
13
|
freemail.hu
|
11
|
14
|
personal.ro
|
10
|
15
|
hotmail.com
|
10
|
Remarcăm la o simplă analiză că există o apetență ridicată față de sistemele de email publice, dar există și județe care au standardizat adresele UAT-urilor din subordine: Dolj și Mureș în mod complet și unitar, Bihor, Mehedinți, Prahova, Timiș în mod parțial.
În urma lansării campaniei de email, am identificat că adresele de email ale domeniilor prefecturaprahova.ro și judetulolt.ro nu sunt funcționale.
S-a întâmplat să identificăm și primării care nu au o adresă de email sau un site web propriu, ci sunt găzduite în portaluri de prezentare a acestora. Construirea și întreținerea unui site web propriu sau a unui server de email necesită cunoștințe specializate și relativ scumpe, ceea ce justifică oarecum lipsa lor. Legat de
O primă idee care se desprinde din această analiză incipientă este aceea că ar trebui să existe un cloud guvernamental de tip SaaS în care să fie puse la dispoziția UAT-urilor, cu resurse tehnice limitate, servicii de găzduire web și sau/email. Au fost identificate în analiza noastră mai multe platforme de eGuvernare (dezvoltate de companii private) care vin în sprijinul UAT-urilor pentru componenta de digitalizare. Amintim pe moment: Regista , Cityon, Citymanager , urmând ca la finalul studiului să identificăm toate celelalte soluții utilizate.
Derularea chestionarului
Emailurile au fost lansate, în mod individual sau grupat către UAT-uri folosind tehnici de mail merge, în perioada 23.11.2023 – 27.11.2023.
Chestionarele sunt realizate în platforma Microsoft Forms și conțin 23 de întrebări cu tot cu datele demografice. Timpul estimat de răspuns este de 15 minute.
Pentru o imagine cât mai exactă a modului în care este percepută digitalizarea în instituțiile publice din România avem nevoie de cât mai multe răspunsuri.
După 24 de ore de la lansare, au fost primite 160 de răspunsuri de la UAT-urile din țară, atât din mediul rural cât și din mediul urban. Raportat la numărul de emailuri corecte trimise și numărul de răspunsuri menținem permanent un grafic de monitorizare a procentului de răspunsuri din total.
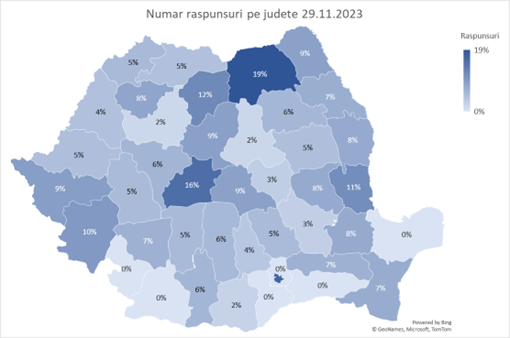
[UPDATE 19.12.2023] Până în prezent am depășit 400 de răspunsuri:
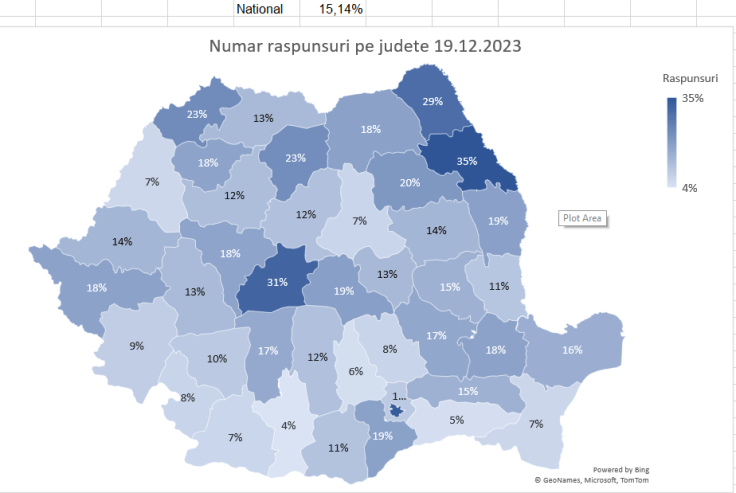
La ora actuală, datorită ajutorului Consiliului județean Iași am reușit să avem un număr mare de răspunsuri, depășind 15% la nivel național.
Cele mai mari probleme cu răspunsurile (sub 8) sunt în județele Olt, Călărași, Mehedinți, Ilfov, Dâmbovița, Constanța, Bihor.
Mulțumim tuturor celor care ne ajută cu răspunsuri pentru a avea o imagine cât mai completă a stării de fapt legată de digitalizare și comunicare între UAT-urile din România și cetățeni.
Perioada de derulare a colectării datelor este între 27.11.2023 și 22.12.2023. În cazul în care sunteți un reprezentant al unei primării din țară și nu ați primit emailul nostru de solicitare răspuns la chestionar, vă rugăm să ne scrieți pe adresa: greavu@uaic.ro
Interpretarea rezultatelor va fi trimisă spre cei care au solicitat acest lucru și va face obiectul unor articole științifice și de informare și conștientizare a domeniului.
Campanie de cercetare derulată în cadrul proiectului: INDI-DeR project – https://cse.uaic.ro/indider