În urma sesizării unui profesionist în Excel am identificat că articolul acesta și metoda propusă sunt eronate pentru că nu generează toate combinațiile posibile.
Ca să respectăm matematica numărul de combinații maxime rămâne limitat la 189 (momentan) având în vedere că valoarea lui COMPIN(190;3) este mai mare decât 2^20.
[/UPDATE]
Astăzi nu am mai reușit să programez o sesiune O oră de Excel. Program foarte încărcat, între care o întâlnire cu boardul RCW (Romanian Creative Week) pentru organizarea în facultatea noastră a celei de a doua ediții a evenimentului: UniCredit Fintech Hackathon
Dar am reușit în timp ce rezolvam alte probleme să găsesc o formă optimizată a matricei de triplete în Excel.
La ce este bună această matrice?
Explicam în articolul din PIN Magazine – Programarea funcțională în Excel Modern că în Excel nu avem o funcție FOR() baza iterațiilor în, cred, toate limbajele de programare actuale. Dar avem soluții detaliate în acel articol. Marea problemă a versiunii prezentate acolo dar și în articolele despre algoritmi din acest blog, este limitarea numărului de elemente dintr-un vector pe care le poți prelucra. În acea primă versiune funcția putea genera matrice de triplete pentru maximum 101 elemente ale unui vector.
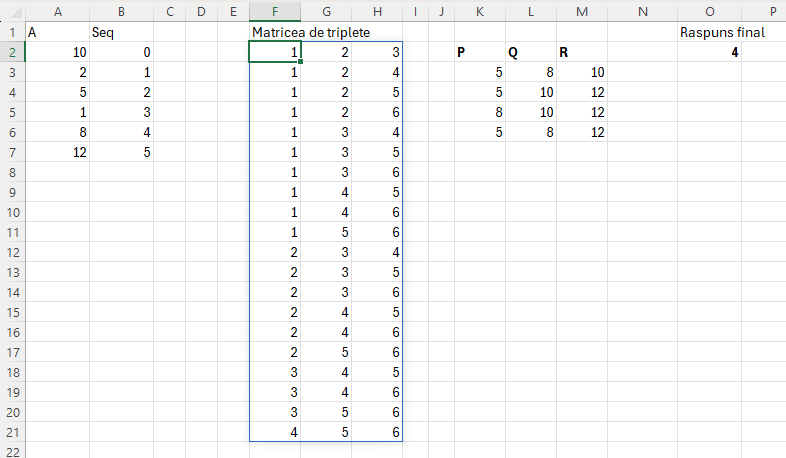
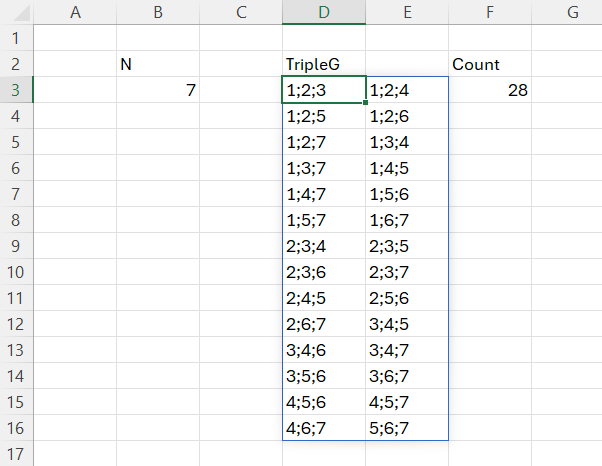
Scopul acestor matrici este intermediar pentru prelucrarea unor seturi de numere luate câtre 3, fără repetiții. Ai un șir de numere și vrei să le adune pe toate cu alte câte două fără să repeți secvența. Cum faci? Ca să iei toate combinațiile unice de câte 3 trebuie să indexezi vectorul, iar pentru asta trebuie să știi ce poziții să apelezi. Acesta este scopul acestui algoritm: determinarea tuturor combinațiilor de poziții ale unui vector, luate câte 3.
Noua variantă elimină funcția SCAN() și introduce o matrice generată. Matricea este foarte mare consumatoare de resuse dar depășește limitele impuse până la versiunile curente.
Exemplificare în Excel
În acestă imagine am prezentat rezultatul pe două coloane ca să ocupe mai puțin spațiu.
în care cheia este variabila matrix care conține funcția MAKEARRAY() care generează dinamic toate combinațiile de numere și asta având doar 2 variabile r și c din care generez cele 3 numere _n1, _n2, _n3. Este o aplatizarea de fapt a unei dimensiuni 3D într-un plan RxC.
Ca să pot sorta elementele am utilizat funcția recursivă freq în care splitez orice valoare rezultată în matrice ca să o pot sorta, după care în variabila finală TripleG păstrez doar valorile unice.
Vizual codul dacă nu apare corect în scriptul de mai sus:
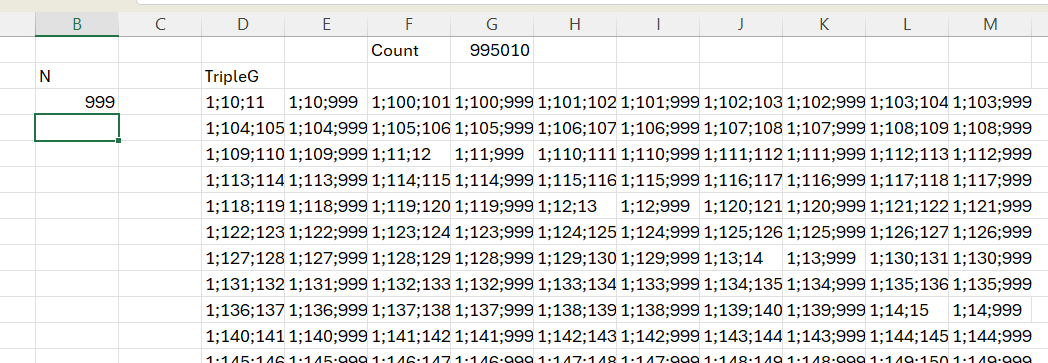
Exemplificare rulare la 999 elemente. Aici se observă că există o mică problemă de sortare a numerelor pentru că ele sunt tratate ca valori text în urma concatenărilor.
Cam asta ar fi. Makearray() rămâne una din funcțiile cele mai surprinzătoare până acum din ceea ce am descoperit recent.
Nu am idee cum s-ar traduce cel mai bine în limba română această metodă. Unii spun că ar fi metoda omidei alți autori metoda ferestrei glisante bidirecționale. Scopul meu este să rezolv în Excel problemele din această categorie, rezolvări care mi s-au părut relativ simple în Excel.
Denumirea vine de la modul în care algoritmul își extinde și retrage fereastra de procesare, similar cu modul în care o omida se mișcă – înaintează secvențial, dar își ajustează poziția astfel încât să acopere eficient o zonă, fără suprapuneri inutile.
În Excel operațiunile acestea le putem face prin indexarea unui vector în funcție de diferite poziții curente de căutare, adresabile prin variabilele R și C ale lui MAKEARRAY() sau cele 3 valori ale matricelor de triplete TripleG (denumire pe care o dau eu acestei tehnici descrise în mai multe ocazii).
Dar înainte de a începe să prezentăm…
Foarte puțină teorie
Pentru a secvenția un vector sau un tabel în Excel avem la dispoziție mai multe funcții, modul în care le utilizează fiecare dintre noi depinzând de experiență, inspirația de moment sau cunoașterea lor.
Principalele funcții pe care le adresez în această secțiune sunt: TAKE(), CHOOSECOOLS(), COOSEROWS(), DROP(), INDEX().
INDEX() în combinație cu MATCH() a fost mult timp considerat o alternativă la VLOOKUP(). Doar că această funcție poate face mult mai mult chiar dinainte de funcțiile dinamice, când artificiul suprem erau funcțiile CSE (Ctrl+Shift+Enter). Combinat cu SEQUENCE() în versiunile moderne de Excel nu mai este nevoie să introducem funcția cu CSE ci funcționează automat. Plus dinamica lui Sequence ne poate duce la soluții extraordinar de spectaculoase. Vezi exemplul din A14 unde aducem ultimele 3 numere din tabel de pe ultima coloană în ordine inversă.
Avantajul lui DROP și TAKE este că pot adresa atât linii cât și coloane prin parametrii 2 și 3. Coloanele și liniile pot fi adresate cu numere pozitive în ordinea coloanelor (1 prima coloana, 2 primele două coloane) cât și negative (-1 ultima linie/coloana, -2 ultimele două linii sau coloane). Choosecols sau Chooserows sunt oarecum mai precise pentru că adresează exact coloana sau linia specificată, dar pot fi și ele combinate cu SEQUENCE() pentru a adresa mai multe linii sau coloane. De exemplu în K6 putem face o optimizare cu sequence în forma: =CHOOSEROWS(COOSECOLS(vNumere;1); SEQUENCE(5;;2))
Personal consider că în cele mai multe cazuri INDEX() este de departe funcția câștigătoare, dar nu sunt de neglijat nici celelalte cazuri de utilizare.
Sortarea valorilor pe linie?!
Într-o zi una din firmele cu care lucrez pe partea de training privat de Excel mi-a trimis o agendă personalizată pentru un curs de Excel Avansat în care unul din puncte era sortarea valorilor pe linii. Eu când nu știu ceva, nu predau sau nu accept deloc clientul. Având în vedere că era totuși un client vechi și important am cerut clarificări… dar nu înainte de a mă uita pe internet dacă există așa ceva…
Ceea ce mi s-a confirmat și am găsit pe Internet mi s-a părut ceva simplist așa că am mers înainte. Dar cazul nu este deloc așa cum ar trebui.
Pentru versiunea manuală de sortare dacă vrei să faci sortarea pe linie:
Dacă vrei să sortezi valorile existente direct în tabel trebuie să parcurgi următorii pași:
Selectează rândul cu datele pe care vrei să le sortezi.
Mergi la „Home” sau „Data” → „Sort & Filter” → „Custom Sort”.
În fereastra de sortare, apasă pe „Options” și selectează „Sort left to right”.
Alege criteriul de sortare (ordine crescătoare sau descrescătoare) și apasă OK.
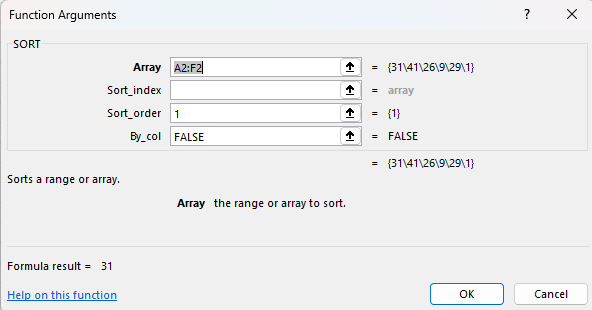
Având în vedere că în Excelul modern, operațiunile manuale sunt înlocuit cu funcții, operațiunea se poate realiza și prin funcția SORT() cu valoarea FALSE pentru parametrul 4.
Și totuși dacă am dori să sortăm toate valoarile crescător pe fiecare linie în parte?
Lucrurile nu mai sunt la fel de simple pentru că funcția sort nu mai funcționează așa cum ne-am aștepta. În Excel, SORT() este dedicat implicit valorilor de pe o coloană, iar ca să ducem o linie în coloană folosim TRANSPOSE().
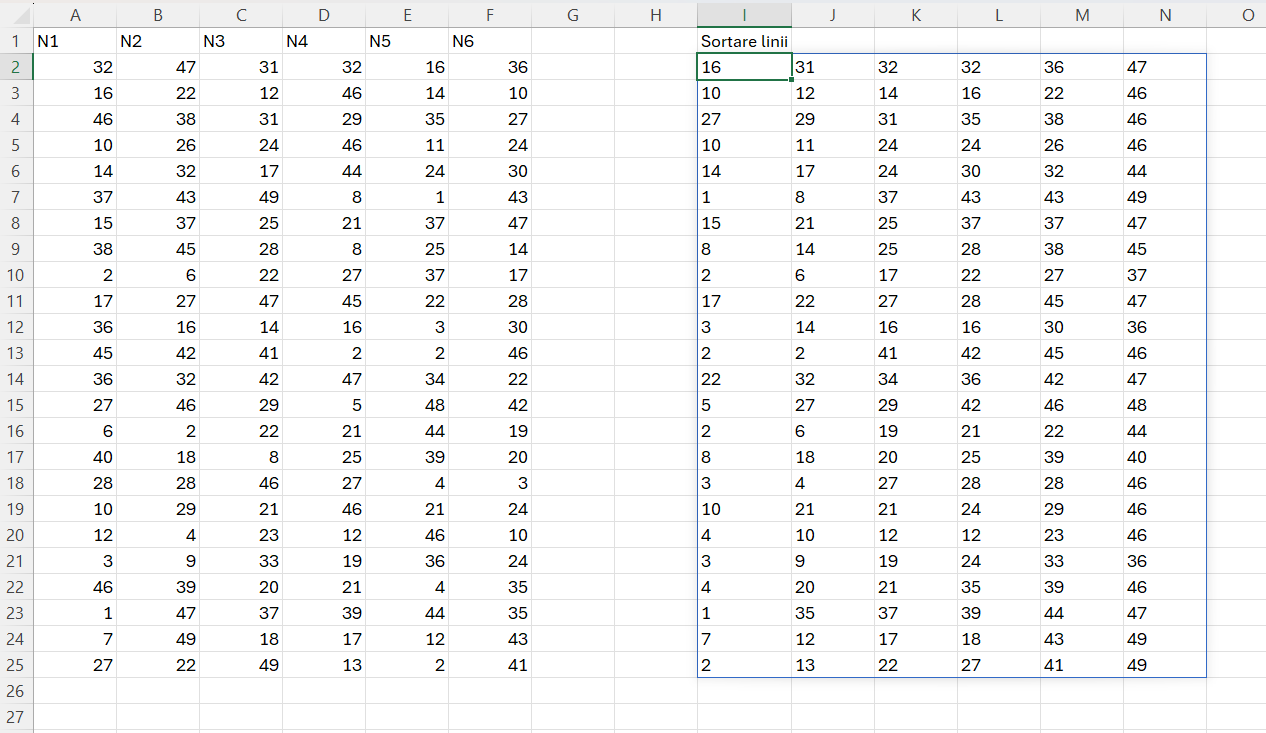
Exemplificare valori random:
Pentru această operațiune introduc în acest articol funcția _fSortRows() care are următorul corp:
arr – este blocul de numere generat aleator cu RADARRAY();
join – unește toate valorile de pe linie pentru a le putea parcurge linie cu linie cu MAP() din rez;
result – este rezultatul cu artificiul de splitare a blocurilor de valori pe linii și coloane.
Această parte am sintetizat-o și într-un scurt clip video.
Acestea fiind spuse, să trecem la rezolvarea problemelor:
Problema AbsDistinct
Problema AbsDistinct presupune determinarea numărului de valori distincte dintr-un array, luând în considerare doar valoarea absolută a fiecărui element.
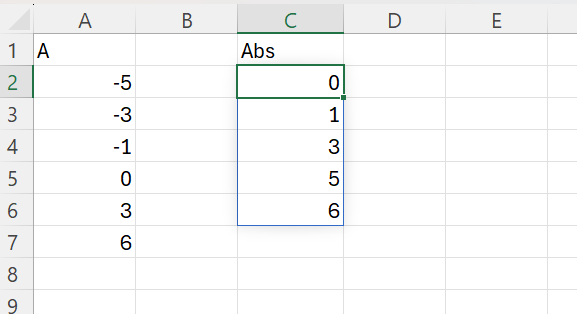
Exemplu Dacă avem următorul array sortat: -5,-3,-1,0,3,6 Valorile absolute sunt: 0,1,3,3,5,6 Valorile distincte sunt: 0, 1, 3, 5, 6 (5 valori distincte).
Rezolvarea este foarte simplă în Excel:
în C2 am utilizat formula: =SORT(UNIQUE(ABS(A2:A7)))
în care ABS calculează absolutul fiecărui număr din vectorul A, UNIQUE() determină toate valorile unice, iar SORT() le sortează ascendent.
Această metodă poate fi utilizată în cazul tranzacțiilor bursiere pentru a identifica variațiile unice absolute ale unei acțiuni într-o perioadă de timp.
Problema CountDistinctSlices
În cardrul acestei probleme avem un șir de numere (A) și vrem să determinăm câte sub-secvențe distincte (numite și slice-uri) pot fi formate, astfel încât toate elementele din fiecare sub-secvență să fie distincte.
Scopul problemei este să aflăm câte sub-secvențe (slice-uri) distincte există, astfel încât niciun număr dintr-un slice să nu se repete.
Rezolvarea problemei nu a fost chiar atât de simplă cum pare la final din cauză că nu am identificat de la început calea cea mai simplă de rezolvare, eu abordând matricial problema cu Makearray(). Doar că matricile nu rezolvă problema sau cel puțin nu am identificat calea corectă.
Rezultatul sugerat de cei de la Codility era dat de următoarele combinații unice: (0, 0), (0, 1), (0, 2), (1, 1), (1, 2), (2, 2), (3, 3), (3, 4) and (4, 4) eu personal neînțelegând la început că slice (0,2) înseamnă valorile 3,4,5.
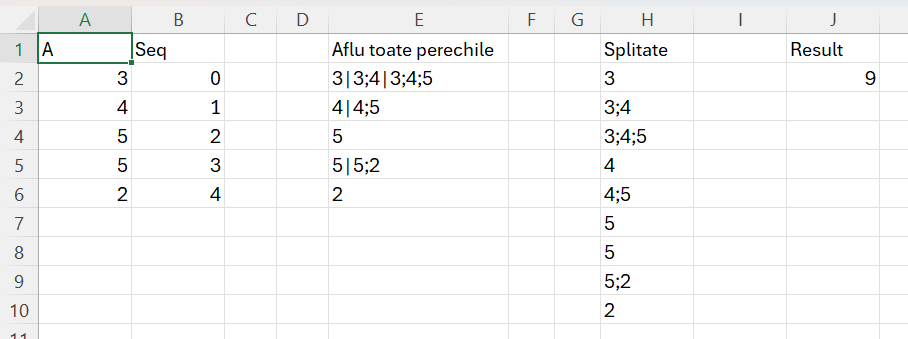
Ca să pot rezolva problema am introdus în E2 o formulă destul de abstractă pe care încercă să o explic:
Ca să pot scana blocul de la poziția 0, apoi de la poziția 1 și așa mai departe, a trebuit să definesc secvența din B2 pe care o parcurg cu MAP(). Apoi pentru fiecare poziție, returnez o combinație de valori de pe blocul A2:A6 pe care-l parcurg cu SCAN(). Partea frumoasă a acestei construcții este dată de faptul că în acumulatorul a introduc întotdeauna valorile în ordinea lor, ceea ce-mi permite să le iau cu acel TAKE() pentru a-l putea compara cu valoarea curentă V ca să identific dacă valorile sunt egale. Scan-ul funcționează la început pentru valoarea 0 a vectorului din B2#. Apoi map-ul duce Scanul mai jos pentru restul de slices.
În H2 folosesc artificiul de splitare: =TEXTSPLIT(TEXTJOIN(„|”;;E2#);;”|”)
Integrate toate operațiunile într-o singură formulă ar arăta:
în care în variabila prerechi calculez acel MAP cu SCAN integrat.
O variantă oarecum diferită a acestei soluții este să oprim SCAN-ul în momentul în care o valoare din A se repetă anterior. Exemplificare:
În acest context când în prima rundă de scanare apare varianta 3 care este deja mai sus, se oprește scan și trece la secvența următoare. Pentru aceasta folosesc o funcție ușor diferită dar cu aceeași logică.
În prima variantă folosesc doar ultima valoare din acumulatorul a iar în varianta 2 compar toate valorile din acumulator cu valoarea curentă. De reținut aici că nu putem utiliza un COUNTIF() într-un SCAN așa că a trebuit să introduc artificiul de a compara oricare valoare din A cu V și transformarea în valori 0,1.
Problema CountTriangles
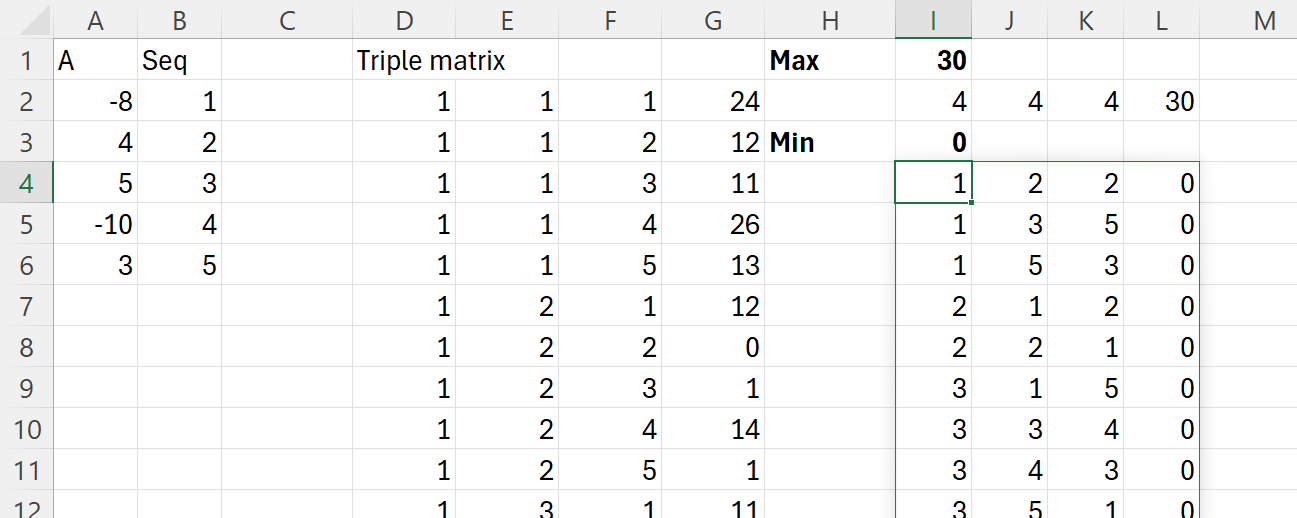
Problema CountTriangles se referă la identificarea tripletelor dintr-un șir de numere care pot forma triunghiuri valide conform inegalității triunghiului.
Inegalitatea triunghiului afirmă că, pentru trei laturi a,b,c ale unui triunghi, trebuie să se respecte condiția: a+b>c , b+c>a, c+a>b Într-un șir sortat, regula devine mai simplă: dacă avem trei elemente A[i],A[j],A[k] unde i<j<k , triunghiul este valid doar dacă: A[i]+A[j]>A[k].
Ca să putem compara oricare 3 elemente dintr-un vector avem nevoie de matricea de triplete introdusă în articolul Modele de algoritmi in #Excel – Sorting (6). De asemenea, problema triunghiurilor a mai fost tratată în articolul menționat la Problema Triangle. De asemenea, a fost descrisă puțin mai pe larg în articolul Programarea funcțională în Excel Modern din pinmagazine.ro una din ultimele reviste de IT, pe care le cunosc eu, disponibilă și offline.
Scopul matricei de triplete este de a genera toate combinațiile unice de câte 3 valori corespunzătoare indexului valorilor pozițiilor unui vector A cu începere de la 1. În articolul din PIN Magazine scriam că această matrice este echivalentului unui triplu FOR din programare. Reamintesc funcția de generare a matricei de indecsi unici.
Această funcție este optimizată în raport cu numărul de elemente din șirul din R1 în cazul acesta pentru că suportă până la 185 de elemente în șir față de 101 în varianta din articolul 6.
Proiecție problemă în Excel
Formula din K3 este bazată pe o variantă a articolului 6 și este:
În care în prima parte se generează matricea de căutare, după care prin funcția recursivă fReqv se indexează vectorul de valori A cu scopul de a determina inegalitățile de tipul a+b>c solicitate de problemă. În felul acesta determinăm că anumite combinații de numere pot reprezenta triunghiuri din punct de vedere geometric.
Problema MinAbsSumOfTwo
Având în vedere că este o problemă cu două valori dintr-un vector care trebuie comparate, soluția optimă în Excel este utilizarea unui MAKEARRAY().
Problema constă într-un vector de numere a cător sumă în format aboslut trebuie să fie cea mai mică. Formal, dacă avem un array A de dimensiune N, trebuie să determinăm: min(|A[i]+A[j]|) unde 0≤i≤j<N.
în care matricea generată cu MAKEARRAY indexează vectorul arr pentru fiecare combinație de linie și coloană.
O variație a acestei probleme care nu există pe Codility este să determin mimimul sau maximul absolut a trei valori din vector. Această problemî în Excel ar arăta:
în care am utilizat din nou matricea de triplete, dar de data aceasta cu scopul de a păstra toate valorile posibile în matrice nu doar valorile unice.
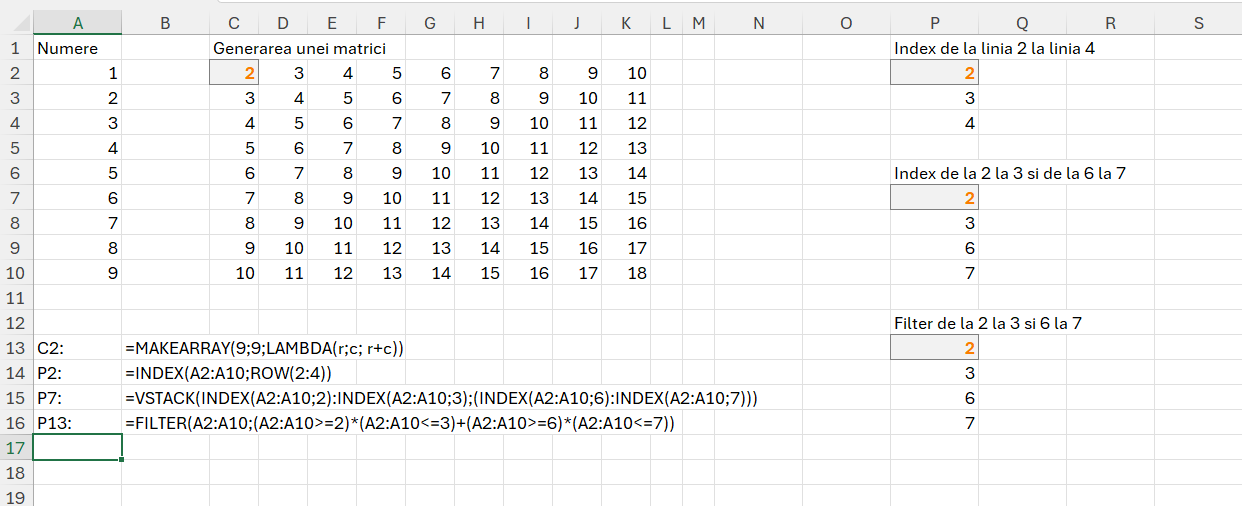
Pentru rezolvarea problemelor din acest articol am ales să folosesc cu precădere funcția MAKEARRAY() care poate avea o putere nebănuită de a transforma un vector liniar într-o matrice dacă reușești o proiecție corectă. Sintaxa funcției:
=MAKEARRAY(rows; columns; function) în care rows este numărul de linii care se vor genera cu începere de la R1 , columns la numărul de coloane din tabelul rezultat iar function este o funcție lambda() cu doi parametri: rows; columns.
După cum se observă în C2 este generată o matrice cu 9 linii și nouă coloane, pentru fiecare celulă realizându-se calculul r+c, însemnând valoarea rândului cu valoarea coloanei.
Celelalte funcții le-ați mai întâlnit. Mai multe detalii despre Filter puteți găsi în articolul de demult: Funcția Filter() din #Excel 365. Funcția Index() mi-a dat ceva de furcă la problema a treia… dar să ajungem acolo.
Să nu uităm că în algoritmică elementele unui vector încep de la 0, dar în Excel majoritatea operațiunilor de indexare/filtrare/cautare încep de la valoarea 1.
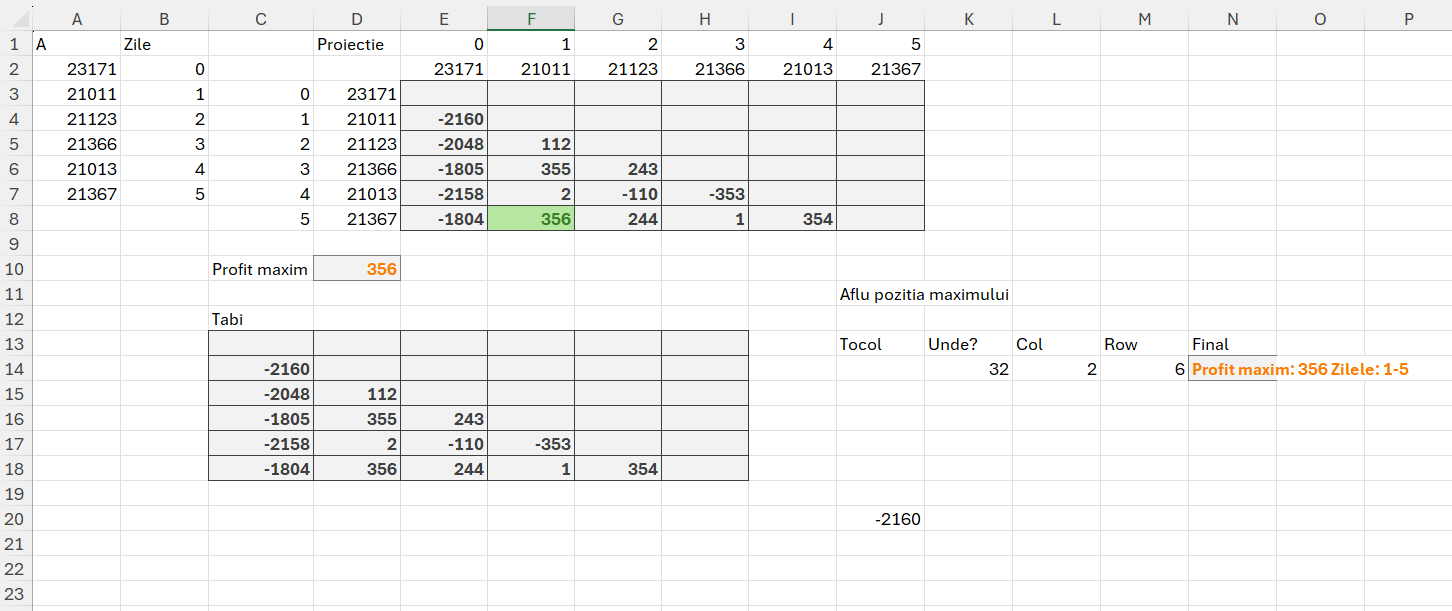
Problema MaxProfit
Face parte din categoria problemelor care analizează secvențe și se concentrează pe identificarea profitului maxim care poate fi obținut printr-o singură tranzacție de cumpărare și vânzare a acțiunilor.
Descrierea problemei: Ni se dă un vector A care conține prețurile acțiunilor în diferite zile. Trebuie să găsim profitul maxim care poate fi obținut cumpărând acțiunile într-o zi și vânzându-le într-o altă zi ulterioară. Dacă nu este posibil să obținem un profit (de exemplu, prețurile scad sau rămân constante), profitul ar trebui să fie considerat 0.
Propunerea de rezolvare:
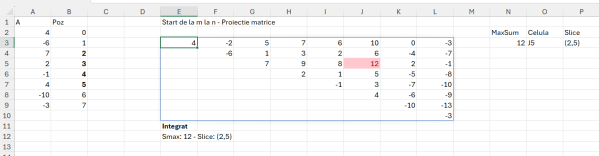
În zona de Proiecție am realizat o implementarea manuală pentru a verifica suma maximă. La urma urmei multe probleme le rezolvăm manual până să ne mai chinuim să facem tot felul de funcții, nu? :) După ce am pus zilele și valoarile pe coloană și linie, la E3 am scris formula: =IF($C3<=E$1;””;$D3-E$2) , întotdeauna zilele trebuie să fie mai mici decât cele pentru care ne raportăm (axa timpului).
Apoi în C13 am proiectat o funcție integrată pentru a face din prima același tabel dar de data aceasta raportându-mă la vectori intermediari prin intermediul valorii lui r și c din makearray. Astfel funcția din C13 este:
în care arr stochează vectorul cu sumele de interpretat, seq generează numărul de zile, tarr transpozează numărul de zile pe coloane ca să le pot folosi ca artificiu în tabi care este de fapt un tabel care indexează valorile din arr pe baza liniei și coloanei curente.
Ulterior în D10 facem un max din acel tabel și avem rezultatul final. Ca să obținem și zilele în care avem acele valori în cazul nostru 1 și 5, atunci trebuie să apelăm șa tehnica de identificare a unei valori într-un tabel, descrisă în articolul: Modele de algoritmi in #Excel– Prefix Sums (5.1)
Problema MaxProfit este o problemă clasică de optimizare cu aplicabilitate în diferite contexte financiare în vederea rezolvării problemelor de maximizare a câștigurilor într-o serie de tranzacții.
Problema MaxSliceSum
MaxSliceSum este o problemă clasică în informatică, care face parte din categoria problemelor de optimizare pe secvențe, adică Maximum Subarray Problem.
Descrierea Problemei: Se dă un vector A de numere întregi (pozitive, negative sau zero). Trebuie identificată suma maximă a unui „slice” (subsecvență continuă) din acest vector. Un slice este definit de două indici P și Q din vectorul A, unde P ≤ Q, și include toate elementele de la A[P] până la A[Q]. Este posibil ca toate numerele să fie negative într-un vector, caz în care slice-ul cu suma maximă va fi cel mai mic număr negativ.
La o primă lectură a problemei am crezut ca este asemanator cu: Problema MinAvgTwoSlice, doar că de data aceasta nu mai luăm perechi de câte două elemente ci pot fi toate elementele… dintr-un șir sau doar o secvență P-Q.
Uneori problemele simple ne dau cele mai multe bătăi de cap, așa că a trebuit să mă documentez mai bine, și așa am aflat că de fapt această problemă mai este cunoscută și ca problema subșir de sumă maximă sau Algoritmul lui Kadane, unul foarte cunoscut în lumea programatorilor. Mi-au plăcut foarte mult explicațiile din filmulețul: Algoritmul lui Kadane – Determinarea unui subsir de suma maxima in C++
Să revenim la Excel. După multe încercări și teste am ajuns din nou la funcția Makearray care are o putere nebănuită în bi-dimensional prin parametrii săi r și c din LAMBDA asociat.
În final implementarea algoritmului este ceva spectaculos de simplu și puternic:
În zona de proiecție matrice am creat un array în care pentru fiecare r<=c am făcut suma subvectorilor de la linia curentă până la coloana curentă.
în care pentru fiecare celulă din tabelul 8 pe 8 calculăm suma valorilor indexului dinamic de la r la c. Comparați cu complexitatea din filmulețul cu implementarea în C++ și poate dați o șansă Excelului. :) Dincolo de glumă pe mine m-a încântat mult soluția, dar vom vedea la următoarea problemă că lucrurile nu sunt chiar atât de roz în Excel….
Funcția integrată care extrage și slice-ul cu sumă maximă este:
Toată construcția pare mai complicată pentru că am integrat în fSlice tehnica de identificare a locației unei coloane, în vederea afișării slice-ului maxim. Dar toată cheia soluției este în variabila sarr în care am acel MAKEARRAY descris anterior, doar că de data aceasta dinamic pe baza variabilelor definite la început.
Din păcate pentru multe numere în A, Excelul începe să gâfâie. La 1024 de numere algormitmul merge foarte bine dar la 4096 a început deja să dea semne de blocare. Pentru testare am utilizat funcția de generare array aleatoriu: =RANDARRAY(128;1;-50; 200;TRUE) în care se generează 128 de numere întrgi (TRUE) de la minim -50 până la maximum 200. Limita de numere din A este limita numărului de coloane din Excel (16384) pentru a putea opera matricea de calcule.
MaxSliceSum este util în analizarea datelor financiare (de exemplu, determinarea perioadei în care profitul a fost maxim) sau în analizarea performanței sistemelor (de exemplu, identificarea perioadelor de maximă încărcare sau activitate). Această problemă este importantă pentru înțelegerea optimizărilor pe secvențe și este un exemplu clasic de aplicare a algoritmilor de programare dinamică.
Problema MaxDoubleSliceSum
Problema MaxDoubleSliceSum este o extindere a problemei MaxSliceSum, fiind parte din categoria problemelor de optimizare pe secvențe. Scopul este să găsești suma maximă posibilă a unei subsecvențe formate din trei părți neconsecutive dintr-un vector.
Descrierea Problemei: Se dă un vector A de numere întregi de lungime N (unde N ≥ 3). Trebuie calculată suma maximă posibilă a unui double slice (subsecvență non-consecutivă) definită de trei indici X, Y, și Z (unde 0 ≤ X < Y < Z < N). Double slice-ul este definit astfel: – X este începutul primei secțiuni care este exclusă. – Y este începutul secțiunii incluse în sumă. – Z este sfârșitul secțiunii incluse, care este exclusă din sumă. Suma double slice-ului este calculată ca suma tuturor elementelor din A[X+1] până în A[Y-1] și din A[Y+1] până în A[Z-1]. Rezolvarea algoritmului a fost o mare provocare pentru că indexarea nu funcționează absolut deloc într-un context prea dinamic, de aceea a trebuit să găsesc o altă metodă de rezolvare.
În rezolvarea problemei am pornit de la metoda propusă în Problema MaxProductOfThree doar că de data aceasta nu mă mai refer unitar la poziția lui X, Y sau Z ci trebuie să caut în șirul A valorile echivalente din matrice și să le însumez. În rezolvarea pas cu pas am generat întâi matricea XYZ cu toate combinațiile posibile în care X<Y<Z. Apoi pe bază de indexare în I4 am calculat suma elementelor. Funcția utilizată linie cu line:
variabilele x, y și z sunt preluate pentru fiecare linie apoi fac suma prin indexarea de la X+1 la Y-1 și de la Y+1 la Z-1. Merge destul de bine dar nu am reușit să le integrez în aceeași funcție pentru că modelul este prea elaborat pentru a putea să funcțineze funcția INDEX():INDEX().
Ca să pot identifica și studia care sunt valorile care compun rezultatul am creat coloana intermediară K în care am unificat prin aceeași tehnică de indexare dinamică a vectorului A, pe baza valorilor din matrice.
Unificarea într-o singură formulă a fost un coșmar, insistând pe INDEX():INDEX() și câteva zeci de variante de funcții recursive. Până la urmă am realizat că FILTER() cu criterii multiple este mai fezabil pentru că returrnează blocuri de celule însumabile.
variabila matrix este definită în articolul Problema MaxProductOfThree și este utilizat doar pentru a putea genera matricea de căutare cu X<Y<Z toate combinațiile posibile.
tabf este de fapt tabelul cu coloana A și secvența de numere în format de start de la 1 pentru a putea să realizez indexarea pe această coloana.
slice este utilizată pentru a putea genera perechile de x;y;z în formatul array cu start de la 0 rezultatul fiind afișat ulterior în tabfin.
fcautxy este o funcție recursivă pe care o folosesc mai jos în fcautxyz pentru ca putea extrage cu filter valorile din A, stocate pe prima coloana a lui tabf pe care o preiau cu TAKE(). Simbolul * este folosit pentru condiții cumulative în filter(). Sintaxa pe cumulative este Filter(valori; (Cond1)*(Cond2) ). Filter() a fost soluția salvatoare.
fcautxyz este funcția recursivă care face suma prin filtrare, definită în fcautxy dar cu aplicare pe Xy și yz. Aici este artificiul suprem prin care am putut folosi o recursivă în atltă recursivă pentru a adresa din două poziții diferite vectorul A.
summax este un vector de valori intermediare care preia linie cu linie (BYROW) din matrix valorile lui X, Y, Z după care invocă recursiva fcautxyz pentru a calcula suma.
maxsum calculează valoarea maximă obținută pe summax
tabfin este tabelul final în care unesc valoarea maximă cu slice după care în rezultatul afișat introduc un nou FILTER de data aceasta pe tabel, în care valoarea obținută să fie egală cu maximum obținut în maxsum.
Huh… a luat ceva timp… dar merită efortul… cu toate că la testare am avut neplăcuta surpriză să constat că numărul maxim de numere din A este de 101… de ce? pentru că rădăcina cubică a numărului maxim de linii din excel (1.048.576) este aproape 101,5…
Aici ajungem la prima limitare a Excelului în rezolvarea acestui tip de probleme. Voi reveni cu o imbunătățire a matricei de triplete care funcționează până la 185 de linii. Veți vedea de ce.
Ca aplicații practice pentru această problemă mă gândesc acum la finanțe, identificarea intervalelor de creștere și scădere a valorii acțiunilor, pentru a găsi cele mai profitabile perioade de vânzare și cumpărare. sau analiza datelor pentru găsirea secvențelor de date cu cea mai mare variabilitate pozitivă, utile în detectarea anomaliilor sau în analiza trendurilor.


")