Îmi ești dragă ca lumina ochilor mei!
Probabil una din cele mai de presus expresii ale iubirii, rostite de multe ori fără semnificația profundă pentru mulți dintre noi.
La ora actuală se estimează că la nivel mondial sunt peste 36 de milioane de persoane nevăzătoare, din care aproximativ 100.000 în România. Sunt convins că există pe lumea asta multe aplicații software care-i ajută pe mulți să învețe să scrie și să citească în limbajul Braille. Vedem și noi astfel de simboluri prin din ce în ce mai multe locuri civilizate și nu le înțelegem semnificația.
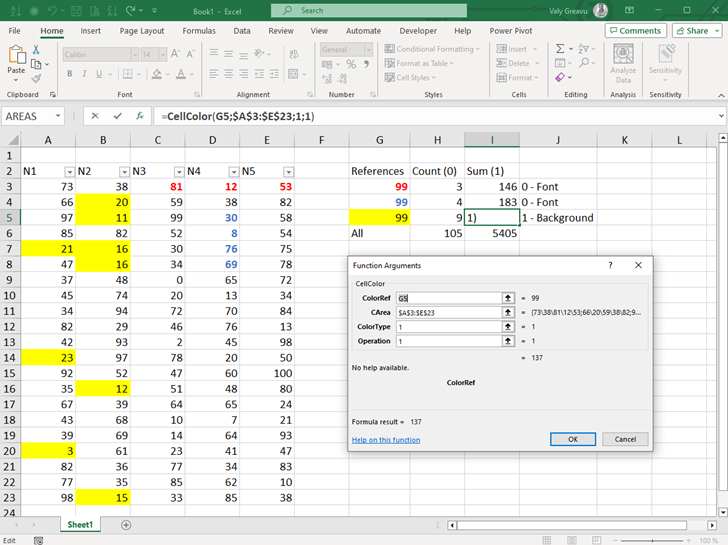
Acest articol este o propunere de utilizare cu scopul de a genera text tipăribil în format Braille (vezi imagine 1). Există mai multe site-uri pentru a genera text Braille sau dispozitive electronice (foarte scumpe) de a scrie și citi Braille.
În cazul în care cineva de la o organizație a nevăzătorilor dispune de o astfel de imprimantă vă rog să testați și să mă contactați dacă este nevoie de îmbunătățiri asupra aplicației.

Fișierul poate fi deschis de la adresa: https://1drv.ms/x/s!ApGubfWFh8NurOhXSganso3njoqMmg?e=ZVGZ3o
Pentru a putea vedea cardurile generate ar fi indicat să activați partea de Turn on images.
În fișierul Excel am folosit noua funcție IMAGE() care permite aducerea unei imagini de pe internet într-o celulă și a efectua operațiuni cu ea.
În fișier, textul poate fi editat doar în zonele dedicate. Fișierul este creat în versiunea Excel din Microsoft 365 deci nu poate fi utilizat pe calculatoarele personale dacă nu dispuneți de o astfel de licență.
Fișierul este în editare publică, pentru a permite tuturor testarea. Orice utilizare în alte scopuri decât cele dedicate excedă responsabilitatea autorului.
UPDATE 17.08.2023
Mulțumesc tuturor celor care au distribuit acest articol. Am avut deosebita plăcere de a discuta cu oameni foarte faini legat de utilitatea acestui exercițiu și despre experiența lor cu lumea IT. În sinteză oamenii sunt bine, dar dacă fiecare dintre noi s-ar putea implica mai mult, ar fi și mai bine.
Cel mai mult m-a ajutat la validare și completare cu caractere românești domnul Aurel Pătru, profesor nevăzător la Liceul special Sfânta Maria din Arad.
Braille pentru ei este important pentru a putea citi în diferite locuri, dar cel mai mult îi ajută funcțiile de accesibilitate din sistemele de operare. Ei folosesc aceste funcții atât pe calculatoare/laptop-uri cât și pe telefoanele mobile. Au o nevoie de comunicare la fel ca toți ceilați și personal mă bucur că suntem împreună pe Internet sau alte canale de comunicare.
Astăzi am avut plăcerea să discut și cu dl Dan Patzelt de la http://www.tactileimages.org/ și mi-a povestit mult despre cum încearcă ei să ajute nevăzătorii și provocările tehnice și financiare pe care trebuie să le depășească.
Dincolo de exercițiul meu, care și-a atins scopul, utilitatea Excelului creat… nu este la fel de mare pe cât o credeam la început, pentru că ei scriu textul în clasic iar echipamentele de imprimare fac translatarea în alfabet Braille automat. :) (de asta probabil sunt și atât de scumpe).
Am actualizat fișierul Excel cu diactitice, cu specificarea faptului că sunt probleme la interpretarea literelor mari pentru diacritice. Acestea au același cod ASCII în Excel atât pentru litere mari cât și pentru cele mici… De asemenea, am modificat puți partea de printare în carduri pentru a răspunde cerinței de a avea maxim 32 x 18 carduri (cum le spun eu) pe o pagină A4.
END UPDATE
Povestea mai pe larg
Mă antrenez pentru Campionatul mondial de Excel eSports: https://www.fmworldcup.com/excel-esports/ Chiar vreau să ajung în primii 50 din lume, deci trebuie să trag tare.
Una din teme este manipularea caracterelor și codurilor prin funcțiile CHAR(), CODE(), UNICODE() și UNICHAR(). De asemenea sunt foarte importante funcțiile de parsare text și tabele, coloane, rânduri și reunificarea lor.
Studiind codurile unicode am descoperit și codurile pentru caracterele Braille. Fiecare simbol Braille reprezintă un set de puncte aranjate într-o matrice de 2×3. Aceasta oferă o structură uniformă pentru litere și cifre. Cu toate că majoritatea literelor majuscule sunt reprezentate printr-un singur simbol Braille, cifrele sunt reprezentate prin două simboluri alăturate. Acest lucru ajută la distingerea clară între cifre și litere într-un text Braille, reducând astfel confuzia și greșelile de interpretare.
Mai auzisem despre limbaj, dar acum aveam un motiv să abordez problema translatării cu adevărat. În foaia de calcul Sursa se află un tabel care conține ceea ce am găsit pe Braille ASCII – Wikipedia. Sunt mai multe simboluri dar am scos dintre ele caracterele speciale din Germană. De asemenea, în tabelul de pe Wikipedia sunt ceva probleme de reprezentare. Tot în sursa am introdus caracter cu caracter sursa imaginilor pentru carduri. Acestea sunt foarte importante pentru printare. Dacă folosești doar punctuația nu cred că este suficient pentru o imprimantă de acest gen. Pe coloana Dots se află punctuația în format 01 în care fiecare 1 reprezintă un punct de pe matricea de 2×3.
Propunerea mea de limbaj este una destul de simplă și am încercat să mă validez cu site-ul școlii: http://www.spdv.ro/braille/ care mi s-a părut a fi unul din cele mai stabile și sigure. Am folosit și site-uri pentru Engleză: https://wecapable.com/braille-translator/english-to-braille-converter/
Trebuie menționat că în sursă nu am diacriticele din limba română pentru că nu am găsit codurile Unicode pentru ele, neexistând o corespondență între vizual (setul de puncte – Dots) și unicode-ul zecimal de pe coloana DecUni.
Propunerea este simplă și prin faptul că nu este adaptată complexității metodelor de scriere din Engleză. M-am documentat pe site-ul https://en.wikipedia.org/wiki/English_Braille ca să înâeleg până unde se poate ajunge, dar mai este mult de lucru pentru acel format de scriere. Menționez că am interacționat cu „AI-urile” pentru a încerca să înțeleg mai repede și mai bine modul de scriere, dar dacă Bard este un pic mai răsărit ca iON () tot cu ChatGPT am ajuns să mă încurc cel mai tare. Problema majoră a lor este că oferă răspunsuri variate și contradictorii pentru aceleași întrebări. Problemele mele sunt legate de seturile de caractere Unicode, restul până la 256 din formatul Engleză (gradul 2), pentru care nu găsesc codurile cu echivalența, iar ChatGPT mi-a oferit variante și variante care mai de care mai lipsite de încredere, așa că pe moment am renunțat la ele. Dacă are cineva corespondența simbol – Unicode, Meaning vă rog să mă contactați.
Principala provocare a fost să înțeleg de ce sunt diferențe de reprezentare între Engleză și Română. De exemplu pentru Engleză literele mari sunt prefixate de cardul 000001 (~6) iar în română de cardul 000101 (~46). Aceasta este și propunerea articolului. De asemenea, există tehnici de scriere în care se scrie totul cu litere mari și literele mici sunt prefixate cu card specific.
Cel mai greu din punct de vedere tehnic mi-a fost să reprezint numerele dintr-un text. Numerele și în română și în engleză (grad 1) sunt prefixate de cardul 001111 (~3456) echivalentul # (diez) din setul de caractere ASCII.
Pentru asta am studiat separate descompunerea unui text în litere, apoi ca să-l pot compara cu litera anterioară sau următoare l-am generat în coloană separate. Am identificat așadar când apare prima literă într-o coloană și în acest caz i-am introdus un # (diez).
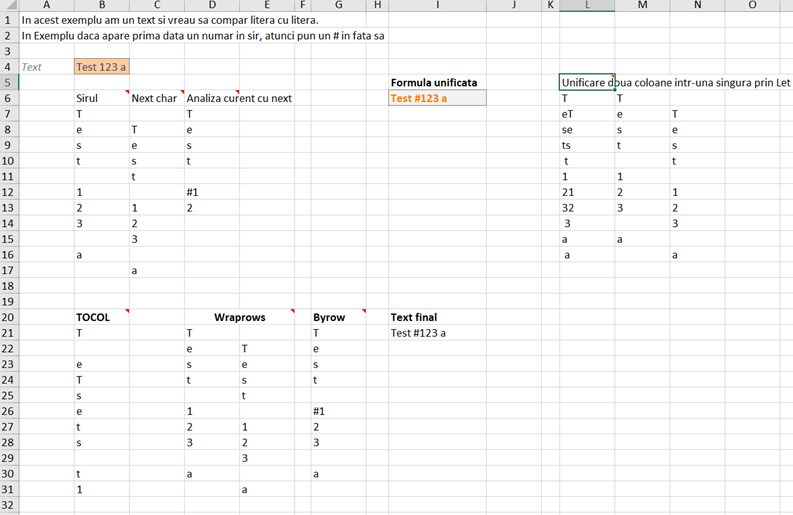
Formula din D7: =IF(ISNUMBER(–B7);IF(ISNUMBER(–C7);B7;”#”&B7);B7)
Pentru a descompune un text în fiecare literă a sa, am folosit funcția MID() cu SEQUENCE()
Formula din B7: =MID(B4;SEQUENCE(LEN(B4));1)
Ca să pot ulterior să o folosesc într-o singură funcție cu LET() a trebuit să pun cele două coloane pe o singură coloană, în format linie cu line (rows) apoi să le transform într-un nou tabel cu Wraprows() ca să pot să aplic fiecărei linii formula inițială din D7 folosind funcția BYROW().
Surpriza a fost că în momentul în care am încercat să le unific, opțiunea de TOCOL() din două variabile de tip coloană nu funcționează, așa că a trebuit să unesc textul celor două coloane în formatul: col1&col2 (rezultat în L6) după care să aplic o altă funcție decât MAP() sau BYROW() care nu funcționează pentru splitare. Astfel ca să pot splita o coloană în mai multe coloane (linie cu linie) a trebuit să construiesc funcția din M6:
Care mi-a permis să fac un tabel cu două coloane și căruia să-i pot aplica un BYROW() cu funcția din D7.
=LET(
Data; L6#;
LenData; LEN(Data);
Rows; COUNTA(Data);
NumCols; 2;
Tabel; SEQUENCE(Rows; NumCols; 1; 1);
CharIndex; MOD(Tabel - 1; LenData) + 1;
CharPosition; INT((Tabel - 1) / LenData) + 1;
INDEX(MID(Data; CharIndex; 1); CharPosition; SEQUENCE(1; NumCols))
)A fost hard dar sper să se fi meritat și să fie de ajutor cuiva!
Pentru întrebări și comentarii puteți folosi secțiunea dedicată din site!
O zi luminoasă tuturor!
 custom VBA function in Excel")