
Acest articol pune la dispoziția cititorilor o metodă de interpretare a textelor, extragere date și numărare a lor, folosind Microsoft Excel 365. De menționat că există instrumente superioare pentru această procedură, scopul meu de a folosi Excelul fiind unul de îmbunătățire a tehnicii de creare a formulelor complexe în Excel.
Tehnica wordcount este utilă pentru a evalua lungimea sau densitatea textului și poate fi utilizată în diferite contexte, cum ar fi analiza de texte sau de documente, pentru a evalua complexitatea sau pentru a verifica dacă un text se încadrează într-o limită de cuvinte. In mod obișnuit, această tehnică se bazează pe algoritmi de procesare a limbajului natural (NLP) și implică împărțirea textului în cuvinte și numărarea lor. În plus, se pot lua în considerare și alți factori, cum ar fi eliminarea cuvintelor de legătură sau a cuvintelor mici (cum ar fi „a”, „și”, „la” etc.), pentru a obține un număr mai precis.
Tehnica wordcount poate fi realizată manual, prin numărarea cuvintelor pe care le vedeți pe o pagină, sau poate fi efectuată automat, prin intermediul unor instrumente specializate sau software de procesare a textului. Rezultatul poate varia în funcție de tehnica și instrumentele utilizate.
În exemplul pe care vi-l propun am preluat primele 2000 de paragrafe de text din Preludiul Fundației de Isaac Asimov (pentru generația TikTok, este vorba despre o carte SF ). În fișierul pus la dispoziție aici, am păstrat doar primele 500 de linii.
Un instrument gratuit destul de interesant pentru wordcount poate fi accesat on-line la adresa: https://www.online-utility.org/text/analyzer.jsp
Comparativ rezultatele obținute pe primele 2000 de paragrafe:
| Excel | Text analyzer |
 |
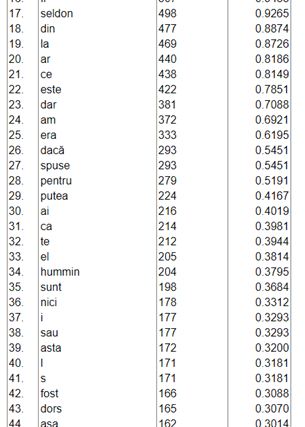 |
Diferența de apariții pentru personajele principale este destul de mică, ceea ce îmi confirmă faptul că metoda aplicată în Excel este fezabilă. Problema este consumul de resurse și procesor pentru a interpreta cantități mari de text, Excel nefiind un instrument dedicat pentru analize volume mari de date.
Etapele implementării în Excel
Dacă ați descărcat fișierul WordCount – Excel 500.xlsx, veți observa că are 3 pagini și definită o singură formulă Lambda() în Name manager. Funcția de substituție fReplace2 am definit-o în articolul: Recursive Lambda() sau cum să scapi de „cârnații” de Substitute() de Substitute() în #Excel și este folosită cu scopul de a elimina caracterele speciale, diacritice și o serie de cuvinte de legătură. Cuvintele și caracterele sunt înregistrate în foaia de calcul Lambda. Lista de acolo poate fi modificată după caz. La momentul scrierii acestui articol este posibil ca problemele de performanță pe volume mari de text să fie cauzate de funcția Offset() utilizată în fReplace2, pentru că odată cu creșterea numărului de cuvinte de eliminat funcționează din ce în ce mai greu. Aici se impun ceva optimizări.
În foaia de calcul Textul începând cu celula C2 am utilizat funcția:
=LET(result;
UNIQUE(LOWER(TEXTSPLIT(
fReplace2(A2;Lambda!$A$2;Lambda!$B$2);" ")));
FILTER(result;result<>""))
în care variabila result definită cu funcția LET() îmi permite ulterior filtrarea cu FILTER a rezultatelor care nu sunt nule, rezultate în urma înlocuirii acestora cu funcția fReplace2. Am folosit Lower() ca să transform toate cuvintele în litere mici, cu scopul de a preveni duplicarea pe aceleași cuvinte scrise în diferite formate și locuri ale propozițiilor.
Pentru cei care nu doresc să deschidă fișierul Excel, aici imaginea rezultată ca despărțire a textului cu TEXTSPLIT pe baza caracterului spațiu (” „).

Pe coloana B am folosit o funcție simplă de numărare a numărului de coloane rezultat ca urmare a execuției funcției de pe C2.
=COLUMNS(C2#)
Având în vedere că nu știu câte coloane sunt rezultate în urma delimitării textului din A2, modul în care am numărat coloanele trebuia apelat dinamic, de aceea am folosit C2# care reprezintă modul de apelare a rezultatului unei funcții dynamic array.
Numărul maxim de coloane mă ajută ulterior în centralizarea cuvintelor în mod dinamic în funcție de textul introdus de utilizator în coloana A.
În foaia de calcul Analiza am două zone: zona de cuvinte unice și zona de filtrare a cuvintelor pe baza unui anumit număr de apariții:

Funcția utilizată pentru a obține cuvintele unice este destul de complicată. Aici am primit puțin ajutor de la ChatGPT, dar destul de greu cu el. Cel puțin partea de INDIRECT nu a reușit să o folosească.
=UNIQUE(
LET(result;
SORT(LET(
data;INDIRECT("Textul!R2C3:R"&COUNTA(Textul!A:A)-1&"C"&MAX(Textul!B:B)-2;FALSE);
rows;ROWS(data);
cols;COLUMNS(data);
flatten;SEQUENCE(rows*cols;1;0);
values;UNIQUE(INDEX(data;MOD(flatten;rows)+1;INT(flatten/rows)+1));
values));
FILTER(result;(LEN(result)>3)*(NOT(ISNUMBER(VALUE(result)))))))
În funcția prezentată, definesc o variabilă rezult care va prelua datele sortate din următorul calcul, și care este filtrată pe ultima linie cu un FILTER, prin care exclud cuvintele mai mici sau egale cu 3 caractere (a, și, la etc) și cele care sunt de tip număr.
În al doilea LET() definesc alte variabile fiecare cu calculele lor. Variabila data (mândria mea din această formulă) este definită printr-o funcție INDIRECT complet dinamică în funcție de numărul de linii de text din foaia Textul și maximul de coloane din coloana B. Având în vedere că nu știu care este numărul maxim de coloane am utilizat acest INDIRECT în formatul R1C1 style (parametrul FALSE) de la final.
Variabilele rows și cols devin oarecum redundante pentru că le am deja în indirect, dar le folosesc pentru a simplifica celelalte calcule.
Variabila flatten o folosesc pentru a defini o secvență liniară de numere echivalentă numărului de linii și coloane din data. Rolul său devine un fel de căutare în matrice prin INDEX-ul din variabila values care se raportează dinamic la numărul de linii și coloane din data.
Pe coloana B am funcția de numărare condiționată CountIF()
=COUNTIF(Textul!$C$1:$IJ$2500;A3)
Aici nu am mai construit dinamic cu INDIRECT tabelul de date. Cu indirect funcția ar arăta:
=COUNTIF(INDIRECT("Textul!R2C3:R"&COUNTA(Textul!A:A)-1&"C"&MAX(Textul!B:B)-2;FALSE);A3)
În celula G2: am introdus o valoare echivalentă numărului minim de apariții a unui cuvânt. Având în vedere că zona de cuvinte unice este formată dintr-un array dinamic și o coloană de calcul pe baza lui, nu putem sorta datele după numărul de apariții. În F3: am introdus funcția:
=SORT(FILTER(A2:B9350;B2:B9350>G2);2;-1)
Care asigură sortarea după coloana 2 din blocul specificat, în ordine descendentă (-1) și filtrează valorile după valorile mai mari decât cele specificate în G2.
Cam asta ar fi. Multă muncă, dar un antrenament mental bun. Dacă v-a plăcut sau nu, nu ezitați să îmi lăsați un feedback.
Sper să fie util cuiva!
