În urmă cu ceva ani, unul din profesorii mei preferați (am mai mulți) ne povestea despre chinurile proiectării și implementării unui „motoraș” de repartizare a opțiunilor studenților sau candidaților pe anumite locuri în ordinea mediilor și preferințelor. Prima dată l-a făcut în SQL pentru admiterea la facultate. Ulterior l-a făcut în R. Recunosc că am privit oarecum cu invidie, pentru că în SQL chiar dacă am învățat destul de bine la master, nu am reușit să îl implementez, iar partea de R nu am înțeles-o prea bine, chiar dacă am mai cochetat din când în când.
Însă din momentul în care am început cercetarea profundă a programării funcționale în Excel, am reușit să fac lucruri pe care altă dată doar le visam și asta fără ajutorul generatoarelor de text, care sunt depășite de aceste metode. I-am mai spus lui ChatGPT că în Excel NU există FOR. El o ține pe a lui. Nu recomand! :)
Acest articol este un tribut pentru toți profesorii (unii actuali colegi ai mei) care m-au îndrumat și încurajat de-a lungul timpului să performez.
Fișierul de lucru poate fi accesat și descărcat de la adresa: AlocareOptiuni v1.xlsx. Acest fișier funcționează doar în versiunile Office 365 sau versiunile mai noi care suport funcții dinamice.
Proiecția problemei în Excel

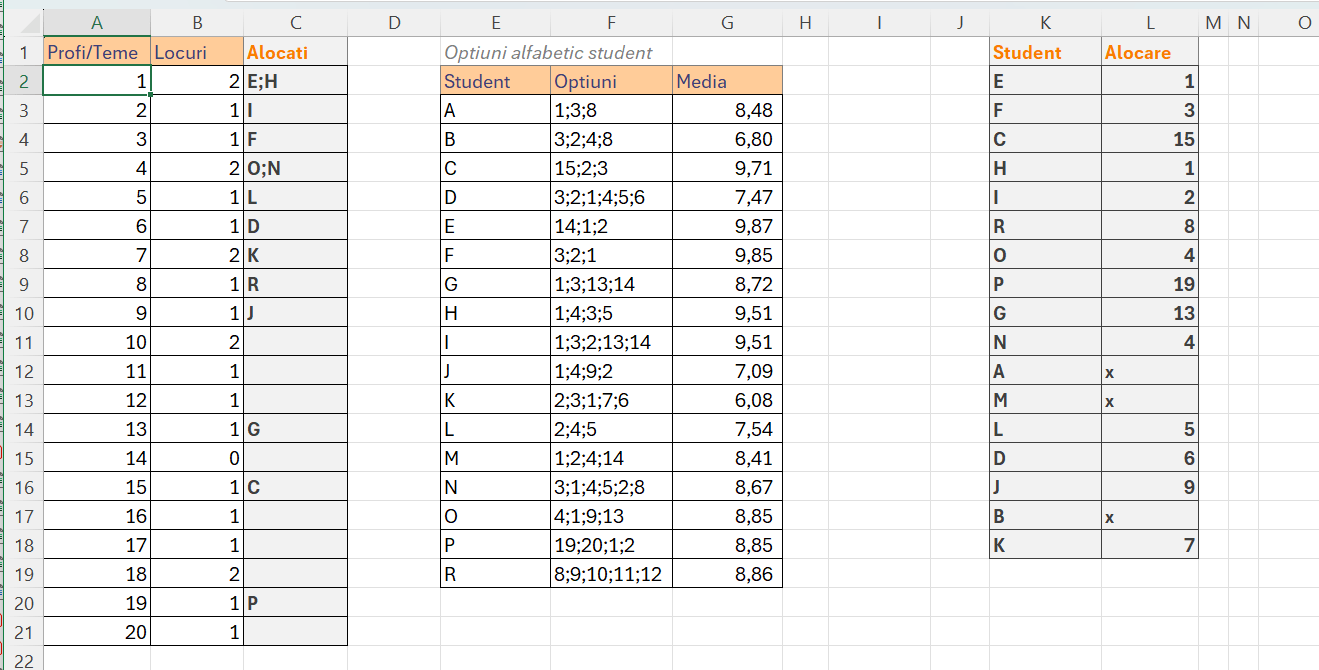
În exemplul prezentat în fișier, se presupune că avem o listă de profesori care au disponibile teme pentru lucrările de licență și un anumit număr de locuri pe fiecare temă. Ca să poată funcționa algoritmul propus, este esențial să codificăm fiecare temă în mod numeric. Numărul de locuri le specificăm tot numeric în dreptul codului fiecărei teme. Temele cu 0 locuri vor fi excluse automat din motorașul de repartizare.
Opțiunile studenților sunt prezentate ca un șir de opțiuni delimitate prin ; (punct și virgulă) în care fiecare număr este codul unei teme. Algoritmul aranjează sursa de date în ordine descrescătoare a mediilor după care face repartizarea după prima opțiune, apoi a doua dacă la prima opțiune nu mai sunt locuri și așa mai departe.
Funcția pe care o puteți întâlni și în fișierul Excel în celula K2 este:

în care:
- locs este blocul de teme de la A2:B21 și care trebuie înlocuit în funcție cu propriile coduri
- optiuni sunt numele studenților cu opțiunile lor și media. Există și posibilitatea de a aborda alocarea și în funcție de principiul primul venit primul servit. În acest caz, dacă ordinea este cea prezentată în foaia de calcul, trebuie să modificăm valorile de pe coloana G cu numere descrescătoare.
- Pentru a reduce complexitatea și numărul de caractere, am definit la începutul formulei, 4 funcții recursive: _fCumulare(tab), _fDecumulare(acumulate), _fLast(x) și _fLastN(x) pe care le utilizez în _scan cu precădere și în result.
Explicam în articolele trecute că un SCAN() nu poate lucra cu tabele ci doar cu o singură valoare. Ca să pot scana totuși tabele întregi, am nevoie de a unifica aceste tabele în valori parsabile.
Prin cod se observă un 999 la linia 8, în _scan și apoi în result. Acest 999 mă ajută să determin dacă o opțiune este în afara numărului de locuri disponibile.
Complexitatea acelui SCAN() poate fi văzută într-o proiecție intermediară aici:
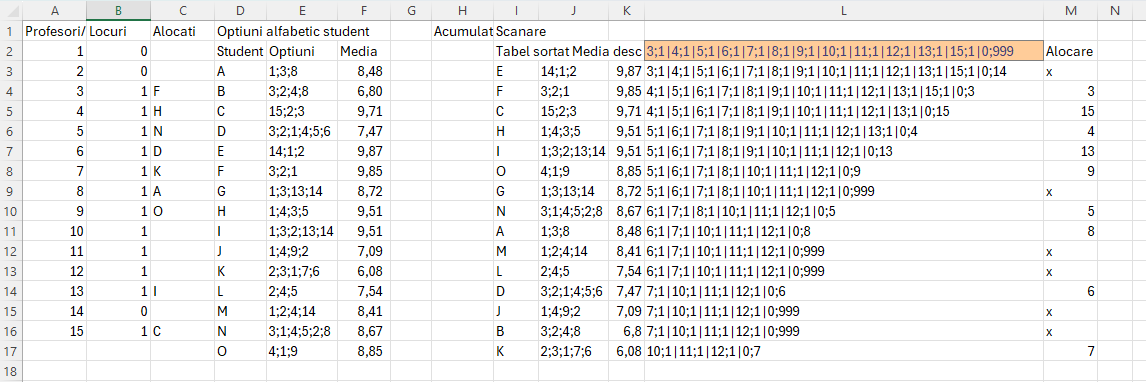
Valoarea de final a fiecărui șir intermediar (acumulatorul din SCAN) este o combinație de 0 și rezultatul prelucrării: 999 sau valoarea opțiunii care îndeplinește criteriile alocării pentru acel student.
În momentul în care am alocat un loc, ca să pot face scăderea lui din locurile rămase am apelat la scăderea a două matrici în variabila ramase (linia 19) care adună rezultatul decumulării acumulatorului curent din intro (linia 12) cu o matrice cu două coloane generată dinamic în funcție de numărul de linii rămase din intro.
Vizual această oprațiune de scădere a matricilor ar fi:

Această tehnică mi-a permis să am oricâte opțiuni din partea unui student și să le tratez pe toate în funcție de ce a mai rămas în acumulator.
Chinul cel mare nu a fost la SCAN ci la integrarea rezultatelor în aceeași formulă. În versiunile intermediare MAP() era soluția logică la calculul variabilei resut. Până la urmă l-am folosit, dar am lucrat doar cu șiruri fără reutilizare funcțiilor de Cumulare și Decumulare. Efectiv nu poți într-un MAP dintr-un LET să folosești rezultatul intermediar al lui SCAN pe care sa-l transformi din nou în tabelar, chiar dacă rezultatul în proiectezi ca valoare atomică cumulată.
În celula C2 pentru a calcula pentru fiecare temă studenții alocați am implementat un simplu TEXTJOIN() de filtrare. Formula din C2: =TEXTJOIN(„;”;;FILTER($K$2:$K$18;$L$2:$L$18=A2;””)). Trebuie să modificați adresele dacă aveți mai multe sau mai puține opțiuni.
Cam asta ar fi.. cazurile de aplicare pot fi diverse, important este să aranjam datele de intrare corect dacă dorim să utilizăm acest „motoraș” de repartizare.
Aștept și accept feedback și sugestii!
Sper să fie util cuiva!
